When pushing the limits of performance, specialization is a must. You obviously cannot win the NASCAR Cup with a street car, not even with one that has a very big and expensive engine. In fact, the engine of a NASCAR car is not really that different from a street car’s. The V8 engine is about four times more powerful than most four-cylinder engines on street cars, but another important difference is to be found in how the engine’s camshaft works.
The cam regulates the amount of fuel and air mixture the engine can pull in and push out, which in turn dictates the power the engine will generate. In a race car, the cam keeps the intake valves open longer at certain higher speeds for additional airflow and peak engine performance. If you did that to a street car, the engine would not work well at lower, street-legal speeds.
Additionally, to turn all this power into maximum speed, race cars have been designed for optimal aerodynamics and downforce, minimum weight with sufficient robustness, and favorable weight distribution. To summarize, the biggest differences between a NASCAR race car and the car in your driveway boil down to specialization.
The same goes for data processing. When pushing the limits of high-performance data processing, you need to specialize to win the race.
Pushing the Limits of Data Processing Performance
A surprising fact when dealing with data-intensive applications, such as retail planning and analytics software, is that the actual computations seldom form the performance bottleneck.
Rather, performance is more often determined by how quickly data can be found in the data storage and fetched from the data storage to the central processing unit (CPU), as well as how efficiently calculation results can be transferred from the underlying database to the application layer. Smart optimization in these areas allows for performance improvements of several orders of magnitude.
Amazingly Fast Analytical Data Processing
Considering that fetching data from disk can be a thousand times slower than fetching data from memory, it is no surprise that in-memory computing (IMC) has become the norm for data-intensive applications, especially when on-demand analytics are involved.
Columnar databases commonly go together with in-memory data processing, for two main reasons:
1. Efficient compression is a must to enable in-memory data processing of large amounts of data. Column-store databases typically contain long sequences of similar or even repetitive data that allow data to be compressed far more efficiently than when using row-store databases. For example, a column consisting of retail sales data would typically contain a lot of small integer values and repetitive zeros.
2. Accessing data in memory still introduces latency, although it is much smaller than when accessing data on disk. As sequential memory access is significantly quicker than fetching data from multiple locations in physical memory, columnar databases deliver superior performance when a lot of data stored in a limited number of columns needs to be processed together. In retail planning and analytics, this is very common. For example, several years of cleansed sales and weather data per store, product and day are needed to predict the impact of forecasted weather conditions on sales.
Data compression is a science of its own, and we will not go into details here. However, a nice illustration of the impact of seemingly innocuous technical choices is that traditional indexing approaches for speedier location of data can result in index tables that are a thousand times larger than the actual compressed database. This obstacle can be overcome by smart engineering, such as the use of sparse indexes for sorted data.
Let the Database Do the Heavy Lifting
Coming back to the race car metaphor, columnar databases, effective compression, and in-memory data processing correspond to the race car’s V8 engine, but it takes more than a powerful engine to make your car win races.
When you have a high-performance database, you also need to use it effectively. This requires optimizing the division of labor between the application and the underlying database.
You need to minimize costly data transfers between the application and the database through what is known as in-database analytics or in-database processing. In addition, you want to make the remaining data transfers as efficient as possible:
1. In-database processing means executing data-intensive computations in the database, close to the raw data, to minimize expensive data movement. When data is highly compressed, it is especially advantageous if computations are done not only in the database, but also without ever storing, even temporarily, uncompressed data.
A principal tool for enabling the performance of data-intensive computations in the database is the database engine. When the database engine is designed to understand the most important and frequent data structures specific to a given domain, data-intensive calculations involving these concepts can be performed in the database, returning only the results of the calculations to the application. This allows for much higher performance than if large amounts of raw data were to be transferred to the application for processing. Ubiquitous retail planning and analytics concepts that are typically difficult to handle for out-of-the box database products include promotions, the relationships between supply chain tiers, as well as reference and replacement products.
2. Even when data-intensive computations are performed in the database, there still remains a need to transfer data between the application and the database. An embedded database design maximizes the throughput between the application and the database. As the application and the embedded database are very tightly integrated and use the same physical memory space, there is no overhead caused by de/serialization, i.e. the translation of data into and from the formats required for storage or transfer.
The principles of sending computations to data rather than data to computations as well as employing embedded rather than external databases are essential for attaining high performance in data-intensive applications, especially when on-demand analytics is required. These principles hold true regardless of whether we are considering a single-server or a distributed data processing architecture.
Returning to our NASCAR example, the database engine and the general integration between the application and database layers take the role of the cam in allowing us to get the most out of our high-performance database.

Strike the Right Balance Between Trade-offs
Compressed columnar databases offer superior performance for querying data, but they are typically not as fast for processing real-time business transactions as row-based, uncompressed databases. This is due to two reasons. Firstly, when data in a compressed database is updated, at least part of the data will have to be compressed again, causing overhead. Secondly, row-based storage allows for faster inserts or updates of transactions because each business transaction is typically stored on one row (i.e. in sequential memory) in the database rather than in many columns (i.e. many different memory locations) in a column-store database.
In retail planning and analytics, the biggest performance requirements come from data-intensive queries used, for example, when comparing historical promotion uplifts for different stores, promotion types and product categories. Therefore, in-memory data processing enabled by columnar, compressed databases is key to great performance. However, data processing cannot be optimized solely from the point of view of analytics. Data inserts and updates also need to be handled in an efficient manner.
This has given rise to what Gartner calls Hybrid Transactional/Analytical Processing (HTAP), where the same data platform performs both online transactional processing (OLTP) as well as online analytical processing (OLAP) without requiring data duplication.
There are several ways to make data updates efficient without hampering the analytics performance of a columnar, compressed database. Two important approaches are:
1. Bundling data updates into batches to minimize the need for compressing the same data blocks repeatedly. Batch processing of data is often understood to mean nightly update runs, which is of course a good option when feasible, but batch processing can also be done in near real-time. Updating a database every minute or even several times a minute with the latest business transactions massively improves performance compared to processing each transaction individually.
2. Using both row-based and column-based data structures to make it possible to take advantage of their respective strengths. New or updated data can first be stored in row-based secondary data structures, enabling quick updates and inserts. These data are immediately available for queries although the primary database structures are updated and recompressed in batches, such as when a batch of business transaction data has been processed.
So, in the same way as a NASCAR race car does not give you the most comfortable driving experience or most economic fuel consumption when commuting to work or taking your kids to their after-school activities, highly compressed columnar databases are not a silver bullet that solve all our data processing challenges. There will always be situations where maximum performance in one area leads to subpar performance in another. Balancing these trade-offs in an optimal way is where specialization really pays off, as it allows you to have a truly in-depth understanding of what matters the most in your use cases.
Great Data Processing Delivers Great Business Value
Although we have only presented a quick peek into how data processing can be optimized for specific purposes, it is probably clear by now how much thought, design and experimentation is needed to deliver the combination of fast on-demand analytics, state-of the art calculations and extreme reliability in a retail setting with thousands of stores, each carrying thousands of products for which new data is constantly generated.
Still, RELEX Solutions is one of very few solution providers that has opted for developing our own database and database engine. Why is that?
Our ambition is to be the best in the world in retail and supply chain planning. Remarkable data processing performance and specialized technology are important factors in achieving this goal.
Let’s illustrate this with some examples.
A New Level of Supply Chain Transparency
Our exceptional computational performance allows us to do things that have previously been very difficult or even impossible to do.
In a recent performance test, we calculated day-level demand forecasts for 450 days ahead and 100 million SKUs, resulting in 45 billion forecasts being produced in 2 hours and 1 minute. This level of data processing speed is required by large retailers to update their replenishment plans on a daily basis to and benefit from including all the latest transaction and planning data, as well as external data such as weather forecasts.
Data processing power is certainly needed for updating forecasts, but it is perhaps even more important for enabling further calculations based on these forecasts. To support proactive planning, we enable our customers to routinely map all future states of their supply chain on the SKU-store/warehouse-day level to understand what inventory will be located where, what orders will be placed and delivered, what volumes will need to be picked and transported etc. Our planning solution calculates this every day, several months or even over a year ahead, while others struggle to get this kind of visibility even for the upcoming week. The improved visibility translates into clear business value in the form of supply chain capacity matching demand much more accurately.
Increasingly Sophisticated Automation
Having full control of the database engine has enabled us to develop our own query language tailored to retail planning and analytics. This allows our customers’ planning experts to easily develop their own queries, including custom metrics, to flexibly answer all their analytics needs without struggling with clunky SQL.
Furthermore, our custom query language has also enabled us to develop a graphical user interface that our customers’ process experts use to create automated queries that can be run regularly or in response to an exception. We call these automated queries Business Rules, but they can also be considered built-in Robotic Process Automation (RPA).
Our customers typically use the Business Rules Engine to let the system make autonomous decisions in well-defined circumstances; to automatically optimize operations; to automate exception management in accordance with their business priorities; as well as to create automatic routines to manage their master data. An example of autonomous prioritization is the virtual ring-fencing needed when the same stock pool is available to both physical stores and online channels. An example of autonomous issue resolution is automated scarcity allocations in accordance with set business targets (e.g. to maximize total sales or to prioritize product availability in stores with narrow assortments) when the system detects that future store orders will exceed projected available inventory.
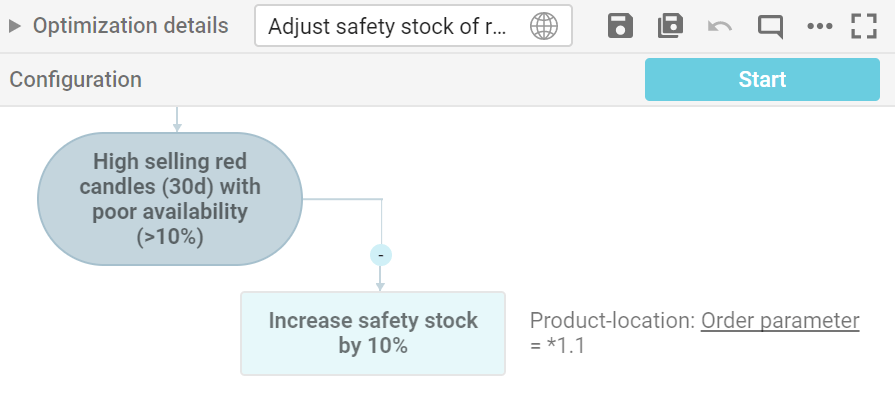
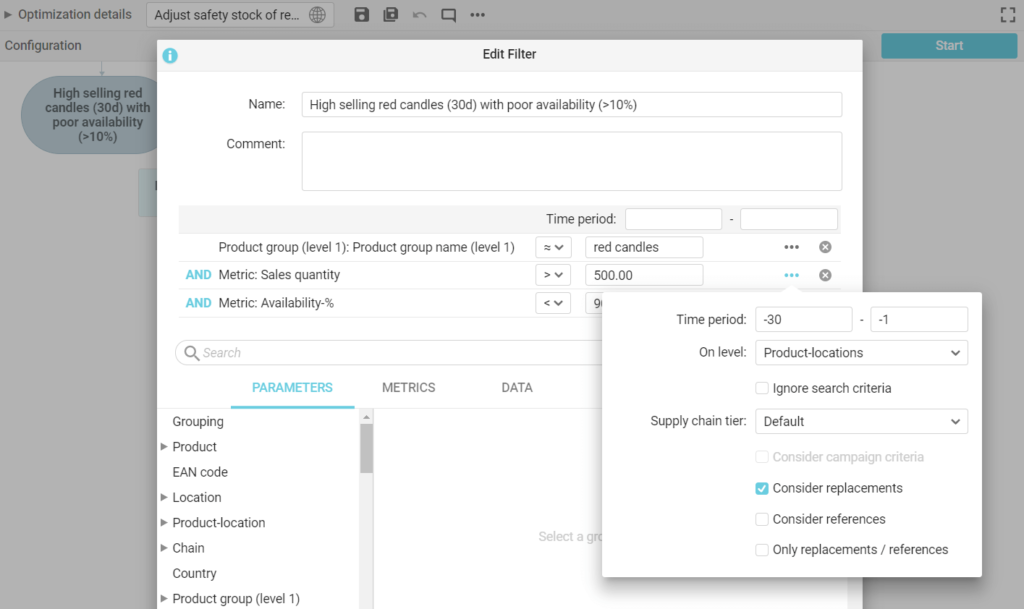
Large retailers can easily have tens or even hundreds of business rules in use to fine-tune and differentiate control of different product categories, store types, suppliers, exceptions etc.
The configuration of the business rules is done without any programming, enabling our customers’ process experts to take full responsibility of development without being dependent on IT resources, budgets or us as the solution provider. Moreover, the configurations do not complicate updates of the underlying software.
Realistic Scenario-planning
Our digital twin technology that supports several parallel working copies makes ultra-granular scenario-planning easier than ever before.
In a nutshell, planners can, when needed, move instantly into a complete copy – a digital twin – of their current production environment (including all data, parameters, customized business rules etc.); make any changes they wish to parameters such as delivery schedules, demand forecasts or the timing of specific deliveries; and review the resulting impact on, for example, capacity requirements in any part of the supply chain on any level of detail. Users can run multiple scenarios and compare them to each other as well as to the current state. When done, users can choose to apply any changes they like to the production environment.
This is an essential part of Retail Sales & Operations Planning, where detailed analysis of impact on individual stores, warehouse sections, days etc. is an inescapable requirement when, for example, preparing for peak seasons. Large food retailers can save millions each year simply by managing the Christmas season more accurately.
The Race Continues
After witnessing a decade of enormous developments in data processing power, making unprecedented amounts of data available to calculations and analysis, the question arises: Are we approaching some kind of saturation point in data processing?
The short answer is: No. We continue to uncover great opportunities to develop the level of sophistication and automation in planning processes and, especially, to tie more closely together different planning processes such as supply chain, merchandise and workforce planning in retail.
However, constantly staying on top of the game requires a team of engineers with a thorough understanding of how all components of the solution, from hardware and software to the characteristics of the data to typical use processes in a specific domain, interact.
Making use of smart technology requires smart people.
Sources
Autotrader: NASCAR vs. Your Street Car: What’s the Difference?