
El Retail es la gestión del detalle a gran escala
La antigua denominación ya lo dice, el retail es la venta al detalle, el comercio minorista a gran escala. Para garantizar unas operaciones fluidas y altos márgenes, los grandes retailers han de estar pendientes de decenas de millones de flujos de productos cada día. Y la previsión de la demanda se sitúa en el centro de toda la actividad de planificación.
Una previsión de la demanda altamente precisa es la única manera que los retailers tienen para predecir qué productos se necesitan para cada ubicación (tienda, almacén, centro de distribución) y canal en un día determinado, lo que a su vez, es la única manera de asegurar una alta disponibilidad para los clientes mientras se mantiene un riesgo de stock mínimo. Aprovechar un pronóstico fiable en las operaciones de retail puede también respaldar la gestión de la capacidad, garantizar la cantidad correcta de empleados en las tiendas y centros de distribución, o ayudar al equipo de compras a gestionar las complejidades de las compras a largo plazo.
Generar pronósticos precisos es, de hecho, bastante fácil en condiciones estables, pero todos sabemos que el retail es inherentemente dinámico, con cientos de factores afectando la demanda de forma continuada. Cada día, los planificadores de la demanda tienen problemas al haber de tener en cuenta un inmenso número de variables, que incluyen:
- Variaciones recurrentes en la demanda como las relacionadas con los días de la semana y estaciones del año.
- Decisiones internas de negocio diseñadas para captar la atención del consumidor y ofrecer una ventaja competitiva, como promociones, ajustes en los precios o cambios en los displays de las tiendas.
- Factores externos como eventos locales, apertura o cierre de una tienda de la competencia en el mismo barrio, e incluso, la meteorología.
Con todos estos datos, no hay planificador humano que pueda tener en cuenta todos estos factores potenciales. Sin embargo, el aprendizaje automático hace posible tener en cuenta el impacto a nivel detallado, por tienda específica o canal de venta. No es sorprendente pues, que actualmente haya tantos retailers transformando sus estrategias tecnológicas hacia una previsión de la demanda basada en el machine learning.
1. ¿Qué es el Aprendizaje Automático y por qué los retailers deberían adoptarlo?
El aprendizaje automático le da al sistema la capacidad de aprender automáticamente y mejorar sus recomendaciones usando solo los datos, sin necesidad de programar. Como los retailers generan enormes cantidades de datos, la tecnología machine learning justifica sobradamente su valor. Cuando un sistema de machine learning se alimenta de datos – cuantos más, mejor – busca patrones. Y aún va más allá, puede utilizar los patrones que identifica en los datos para tomar mejores decisiones.
El aprendizaje automático posibilita que al pronóstico de retail se le pueda incorporar la gran variedad de factores y relaciones que afectan la demanda a diario. Esto tiene una gran importancia, ya que sólo los datos meteorológicos por sí solos pueden estar compuestos por cientos de factores que potencialmente, pueden impactar en la demanda. Los algoritmos de machine learning generan automáticamente modelos de mejora continua usando solamente los datos que se les proporciona, ya sean de nuestro negocio o de flujos de datos externos. El principal beneficio es que un sistema como éste puede procesar conjuntos de datos a escala retail desde una variedad de fuentes, todo sin intervención humana.
Los algoritmos de machine learning no son nuevos – han estado ahí durante décadas. Pero estos algoritmos nunca antes habían tenido acceso a tantos datos o a un poder de procesamiento de datos tan grande. Aunque en el pasado los retailers hayan podido tener dificultades para actualizar las previsiones rápidamente, ahora la tecnología in-memory y el procesamiento de datos a gran escala permiten millones de cálculos de pronóstico por minuto.
2. El Aprendizaje Automático aborda los retos de las previsiones de la demanda del retail
El aprendizaje automático es una herramienta súper potente en un entorno como el de retail, tan rico en datos. Debería aprovecharse en cualquier contexto en el que se puedan usar los datos para anticipar o explicar cualquier cambio en la demanda. En algunos casos, incluso puede completar los datos que faltan.

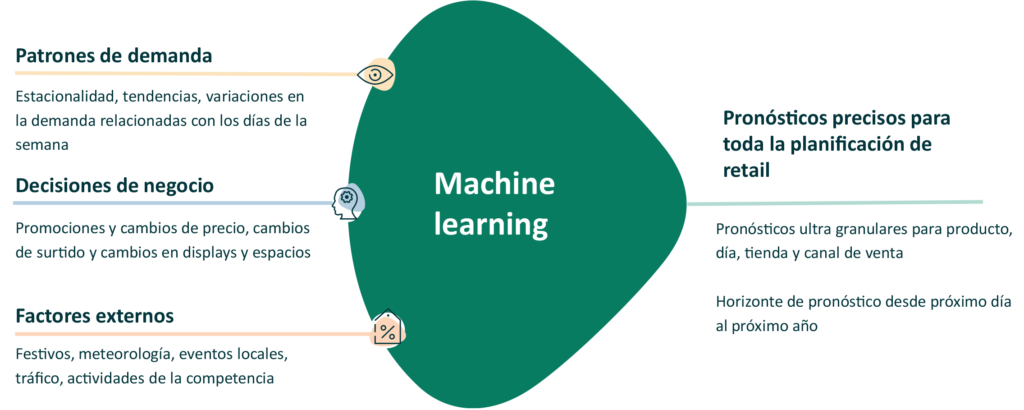
2.1 Día de la semana, estacionalidad, y otros patrones de demanda recurrentes
El modelo de series temporales es un enfoque probado y válido que puede entregar buenos pronósticos para patrones recurrentes, como los cambios en la demanda relacionados con los días de la semana o las estaciones. En nuestra experiencia, los pronósticos de demanda basados en el aprendizaje automático entregan consistentemente un nivel de precisión más alta que los modelos de series temporales. Mientras que los modelos de series temporales simplemente aplican patrones pasados a la demanda futura, el aprendizaje automático va más allá al intentar definir la relación real entre las variables (como los días de la semana) y sus patrones de demanda asociados.
El Machine Learning simplifica el pronóstico de demanda del retail. Al usar modelos de series temporales, los retailers deben manipular los resultados del pronóstico de ventas de referencia para adaptar el impacto de, por ejemplo, las próximas promociones o cambios de precios. Sin embargo, el Machine learning tiene en cuenta todos los factores automáticamente.
Además de tener en cuenta muchos factores, el machine learning también puede captar el impacto cuando interactúan múltiples factores, por ejemplo: la meteorología y un día de la semana. Días cálidos y soleados pueden hacer que aumente mucho la demanda de los productos para barbacoas si coinciden en fin de semana.
2.2 Cambios de precios, promociones, y otras decisiones de negocio que afectan la demanda
Las propias decisiones del negocio como retailer, son también una importante fuente de variaciones en la demanda, desde promociones y cambios de precio a ajustes en cómo se muestran los productos en las tiendas. A parte del hecho de que las empresas normalmente planifican y controlan ellas mismas estos cambios, muchos en el sector son incapaces de predecir su impacto con exactitud.
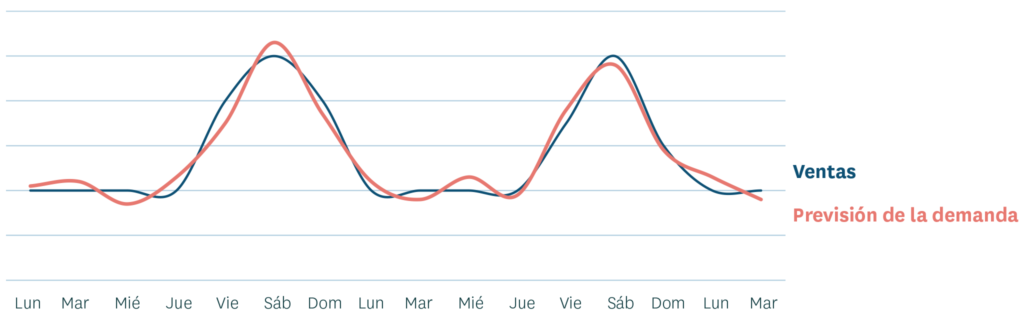
El aprendizaje automático permite que los retailers puedan modelar con precisión la elasticidad de precio de producto, es decir, cuánto afectará un cambio de precio en la demanda de ese producto. Esta prestación es muy valiosa como parte del pronóstico de la promoción y al optimizar los precios de las rebajas para liquidar stock antes de un cambio de surtido o al final de una temporada. Además, los retailers tienen que ajustar los precios de forma regular para que reflejen los precios de los proveedores y otros cambios en sus costes.
En cualquier caso, la elasticidad de precio por sí sola no recoge el impacto completo de los cambios de precios. Un cambio de precio en relación a productos alternativos dentro de la misma categoría a menudo también tiene un fuerte impacto. En muchas categorías, el producto con el precio más bajo captura una cuota de mercado desproporcionadamente grande. Los pronósticos de demanda basados en el aprendizaje automático facilitan considerar la posición del precio de un producto, tal y como se muestra en la siguiente tabla:
En un estudio de 2020 sobre Supermercados de Norteamérica, el 70% de los encuestados indicó que no podrían tener en cuenta todos los aspectos importantes de una promoción – precio, tipo de promoción, o el display en tienda – al pronosticar las subidas promocionales. Pero desearían poder hacerlo.
Aquí también puede ayudar el aprendizaje automático. Al usar previsiones de demanda basadas en machine learning, los retailers pueden predecir con precisión el impacto de las promociones teniendo en cuenta factores que incluyen, entre otros:
- Tipo de promoción, como la reducción de precio o multi compra.
- Actividades de márketing, como los anuncios o la señalización en tienda.
- Reducciones de precios de los productos.
- Presentación de los productos promocionados, como los displays en tienda.
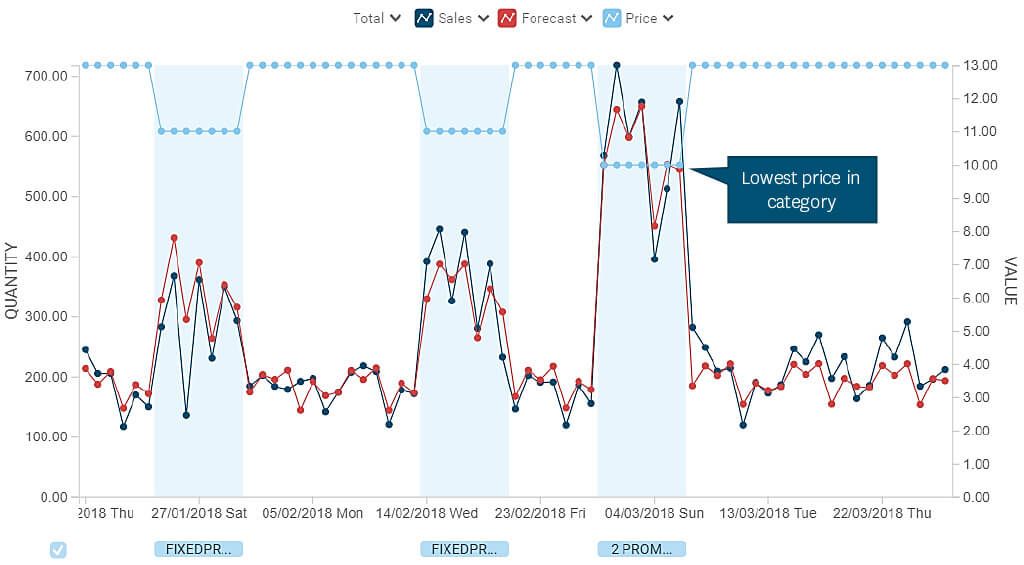
La canibalización de ventas, el fenómeno que hace que el aumento por promoción de un producto cause una disminución en las ventas de otros productos de la misma categoría, es bastante común y también ha de tenerse en cuenta al hacer las previsiones, especialmente para los productos frescos. Por ejemplo, si un supermercado tiene dos marcas de carne de ternera picada orgánica – Vaca Feliz y La Ternera Verde – debería esperar que una promoción del producto Vaca Feliz haga que la compre más gente. Pero como resultado, parte de la demanda de La Ternera Verde se irá a Vaca Feliz. Si el pronóstico de demanda de los productos Ternera Verde no se reduce con precisión, el retailer tiene un gran riesgo de sobre stock que finalmente acabará en mermas..
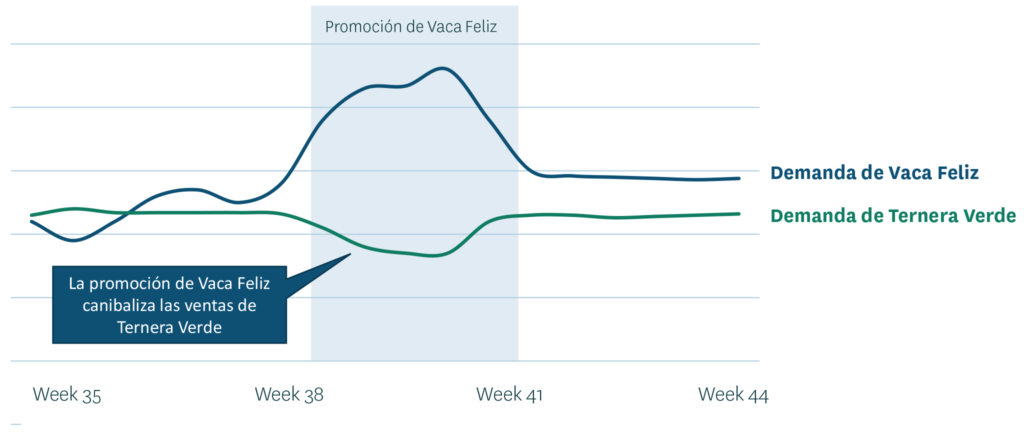
Ajustar manualmente los pronósticos para todos los productos potencialmente canibalizados es algo imposible en la mayoría de los contextos de retail porque el número de productos es sencillamente demasiado alto. Los patrones son normalmente bastante específicos para los surtidos de las tiendas individuales y los patrones de compra. Aquí es donde entra la capacidad de los algoritmos del aprendizaje automático para identificar automáticamente los patrones y ajustar los pronósticos en consecuencia, lo que añade un gran valor.
Por otro lado, una promoción de los productos de Vaca Feliz hará que probablemente aumenten las ventas de algunos de los productos relacionados diferentes a la carne picada, y a esto se le llama efecto halo. Panes para hamburguesas, por ejemplo, tienen una relación obvia y predecible con la carne picada. Lamentablemente, el impacto puede ser tan difuso en el surtido que identificar cada producto afectado se hace casi imposible, incluso con machine learning: pensemos en cebollas, patatas chips, cervezas, kit para tacos, pasta de lasaña, mostaza…o cualquier otro artículo que los compradores puedan asociar con un plato de carne picada. Pero si ni siquiera los sistemas de pronóstico pueden identificar todas las relaciones de halo posibles, lo que sí deberían hacer es permitir que los planificadores puedan ajustar fácilmente los pronósticos para las relaciones que sí saben que existen.
2.3 Meteorología, eventos locales, y otros factores externos que afectan las ventas
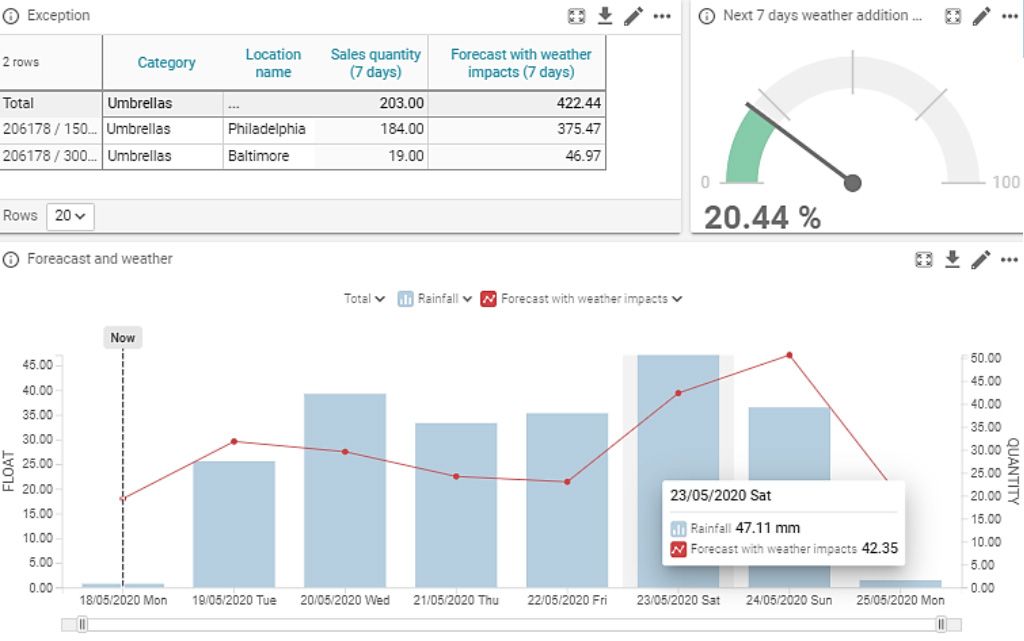
Los factores externos como la meteorología, conciertos y actividades deportivas locales, y cambios de precio de la competencia pueden tener un impacto significativo en la demanda, pero son difíciles de tener en cuenta en los pronósticos sin un sistema que automatice una gran cantidad del trabajo. A nivel general, el impacto puede ser bastante intuitivo. Durante un día cálido, es muy probable que aumenten las ventas de helados, mientras que en la temporada de lluvias, se verá un aumento de la demanda de paraguas, etc.
Pero al observar el surtido completo de retail, el reto se complica aún más, ¿cómo se pueden identificar de manera efectiva todos los productos que reaccionan a la meteorología? ¿podemos tener en cuenta todas las variables que comportan las previsiones meteorológicas – temperatura, sol, lluvias, etc.? ¿El impacto de un día soleado será mayor en verano que en invierno? ¿O es mayor en fines de semana que entre semana?
El uso de los datos meteorológicos en las previsiones de la demanda es un excelente ejemplo del poder del aprendizaje automático. Los algoritmos de machine learning pueden detectar automáticamente las relaciones entre las variables meteorológicas locales y las ventas locales. Pueden mapear estas relaciones en un nivel más granular y localizado que cualquier esfuerzo humano, y también pueden identificar y actuar en relaciones menos obvias, por las que la intuición o el sentido común de las personas podrían pasar por alto.
Cuando a los planificadores de demanda o a los empleados de tienda se les pide que comprueben manualmente las previsiones meteorológicas que pueden influir en las decisiones de compra, se centran en asegurar el suministro de los productos más afectados por el incremento esperado de la demanda, como por ejemplo, los helados en una ola de calor, por ejemplo. Pero ¿alguien tiene tiempo para disminuir ligeramente los pronósticos de helados durante las semanas lluviosas o de aperitivos fríos en verano? Un equipo de planificación que usa machine learning no tiene por qué preocuparse en hacer ajustes de este tipo, ya que su sistema puede sugerirlos de forma automática.
En nuestra experiencia, considerar automáticamente los efectos de la meteorología en los pronósticos de la demanda reduce los errores entre un 5% y un 15% a nivel producto para los productos sensibles al clima y hasta un 40% a nivel grupo de producto y tienda.
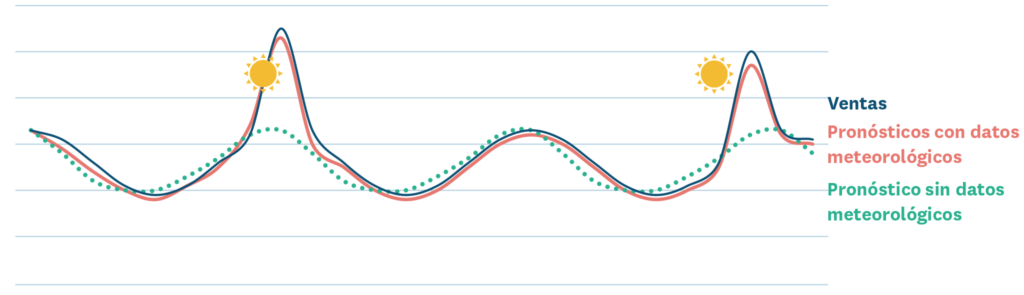
Pero los datos meteorológicos no son los únicos datos externos que podrían o deberían incorporarse en los pronósticos de demanda del retail. Cualquier fuente de datos externos, como eventos locales pasados y futuros (partidos de fútbol o conciertos), datos sobre los precios de la competencia, y datos sobre movilidad pueden usarse para mejorar los resultados.
Como ejemplo, RELEX utiliza el aprendizaje automático para ayudar a WHSmith a comprender mejor cómo los horarios de los vuelos afectaban los patrones de demanda en sus aeropuertos. Al introducir en el sistema los datos externos de las aerolíneas, WHSmith mejoró sus pronósticos y pudo reducir las mermas de sus productos frescos a la vez que mejoraba la disponibilidad
2.4 Factores desconocidos que tienen un impacto en la demanda
Hasta ahora, hemos visto contextos en los que los factores que impactan la demanda – patrones semanales y estacionales, decisiones de negocio, y factores externos – son fácilmente identificables. Pero el machine learning puede ayudar a ajustar los pronósticos incluso en situaciones donde los factores afectantes, ya sean internos o externos, sean desconocidos.
En las tiendas de retail físicas, las circunstancias locales – como la competencia directa abriendo o cerrando una tienda cercana – pueden causar un cambio en la demanda. Lamentablemente, los datos sobre el factor que causa este cambio puede que no queden registrados en ningún sistema. A veces, las decisiones internas de los retailers tampoco se registran, como cuando se amplía la exposición de un producto poniéndolo en un expositor especial además de su ubicación habitual.
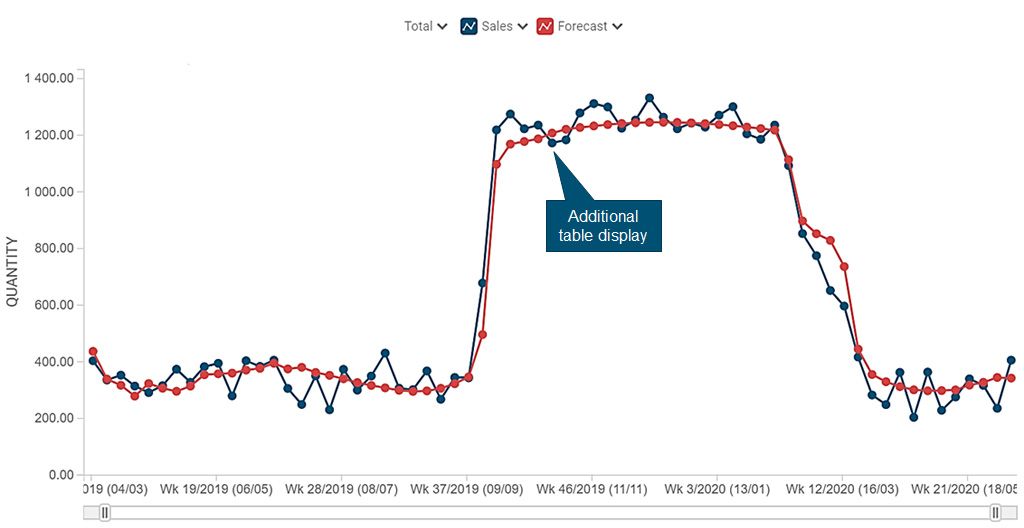
Por suerte, el aprendizaje automático puede ayudar en estas situaciones. Los algoritmos de machine learning pueden proponer tentativamente un “punto de cambio” en el modelo de pronóstico, luego rastrear los datos subsecuentes para rechazar o validar la hipótesis. Esto permite que los pronósticos se adapten rápida y automáticamente a los nuevos niveles de demanda.
Tomemos como ejemplo la tabla de abajo, en el que se ha creado un expositor para un producto además del espacio normal de estantería. Aunque este cambio no se registró en los datos maestros, el sistema fue capaz de relacionar el cambio en la demanda con un cambio en cómo se exponía el producto en tienda.
3. Haz que el machine learning trabaje para ti en la gestión de la demanda
Aunque el aprendizaje automático es cada vez más común, los retailers deberían tener en cuenta algunas consideraciones sobre como usarlo en sus negocios. Algunas consideraciones son específicas para el contexto de retail, mientras que otras, como el nivel de transparencia, por ejemplo, son lo suficientemente genéricas como para aplicarlas a cualquier situación que requiera un trabajo en equipo persona-computadora
3.1 Trabajar con productos de baja rotación
Uno de los retos específicos de retail es que, pese a la gran cantidad de datos de los que se dispone, la cantidad de datos disponibles por producto, tienda/canal, y factores que afectan en la demanda, a veces es muy poca. Incluso si sus ventas anuales son de miles de millones, el volumen total se distribuye entre decenas de millones en flujos de inventarios y cientos de días.
Las ventas de los productos de baja rotación – aquellos productos de los que solamente se venden unas pocas unidades por día o semana – a menudo tienen muchas variaciones aleatorias, y puede ser difícil identificar de forma fiable los patrones de relaciones entre tanto ruido. Con pocos puntos de datos disponibles (decenas o cientos, en vez de miles), diferenciar el impacto de los factores que influyen en la demanda (la meteorología, los cambios de precios, cambios en los displays, o actividades de la competencia) de la variación aleatoria se convierte en un gran desafío.
Cuando los productos con un volumen de ventas bajo introducen una cantidad significativa de variaciones aleatorias, se corre el riesgo de sobreajustar y el algoritmo se vuelve demasiado complejo o contiene demasiadas variables. En situaciones de sobreajuste el algoritmo puede terminar memorizando el ruido, en vez de encontrar la verdadera señal de demanda subyacente. Este modelo sobreajustado acabaría haciendo predicciones basadas en ruido. Podría funcionar excepcionalmente bien si se usan los datos de entrenamiento del modelo, pero extremadamente mal cuando se le pide que incorpore datos nuevos con un comportamiento desconocido. Por lo general, un sobreajuste da como resultado unos pronósticos con valores atípicos discordantes con las muestras, o pronósticos nerviosos, donde el pronóstico reacciona demasiado a cambios menores en los datos.
Además, puede que no sea posible detectar un patrón estacional a nivel producto-tienda para los productos de baja rotación, pero un análisis de las ventas totales a nivel cadena para ese producto puede identificar fácilmente un patrón claro. Este patrón ha de tenerse en cuenta en el reabastecimiento de los centros de suministro y distribución.
Debido a los bajos volúmenes y la dispersión de los datos a nivel producto-tienda/canal en retail, es muy importante que:
- Los algoritmos de machine learning usados sean lo suficientemente robustos como para no entregar resultados atípicos basados en puntos de datos escasos.
- Los algoritmos de machine learning eviten sobreajustes minimizando o eliminando los factores que tienen un impacto en la demanda bajo o nulo.
- Los algoritmos de machine learning se pueden aplicar no solo a nivel producto-tienda/canal sino también a diferentes niveles de agregación (por ejemplo: producto-región o producto-tienda) y con agrupaciones flexibles.
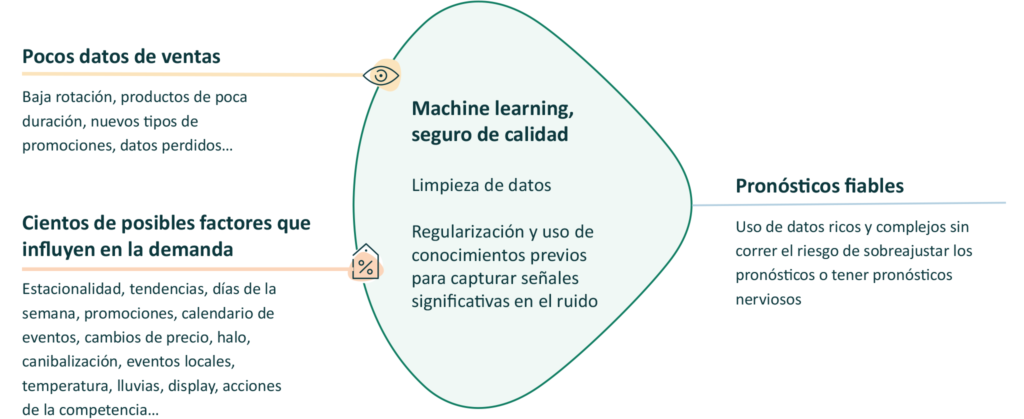
Imagen 9: Para evitar sobreajustes al aplicar el aprendizaje automático a datos dispersos de ventas de retail, el sistema ha de poder: 1) tender hacia la simplicidad al eliminar los factores que tienen poco impacto en la demanda, y 2) suministrar datos significativos que permitan al sistema encontrar relaciones relevantes de forma efectiva.
3.2 Aprovechar la experiencia humana
La crisis de la COVID-19 ha demostrado que los procesos automáticos para las previsiones de la demanda y el reabastecimiento son extremadamente útiles cuando los retailers se enfrentan a perturbaciones a gran escala, ya que la automatización hace que se libere mucho tiempo de planificación. Pero en cualquier caso, los planificadores siguen siendo necesarios para guiar al sistema cuando surgen eventos insólitos que tienen un gran impacto. En estas situaciones, las decisiones deberían ser algo más que tratar de hacer buenas predicciones, los retailers deben evaluar el riesgo comercial de los escenarios positivos y negativos. Para crear una interacción humano-computadora efectiva, ya sea en escenarios tan excepcionales como el provocado por el coronavirus o durante periodos de demanda más normales, los retailers necesitan hacer análisis que permitan llegar a conclusiones y a un plan de acción que los respalde.
Como las previsiones nunca son perfectas, siempre habrá situaciones en las que los planificadores tengan que diseccionar un pronóstico. Cuando los planificadores pueden acceder fácilmente a los factores que se han usado para producir los pronósticos, y entienden cómo se han usado, es más probable que confíen en el sistema para gestionar situaciones de negocio “normales”, y así se pueden centrar en las situaciones excepcionales que son las que necesitan realmente su atención. Los sistemas de caja negra con poca transparencia imposibilitan que se sepa por qué se hacen las recomendaciones automatizadas. Erosionan la confianza del usuario, y a menudo generan tasas de adopción del sistema bajas
Una solución transparente también ofrece a los planificadores información valiosa para futuras mejoras – ya sean mejores datos, la necesidad de una clasificación adicional del producto, o probar nuevas combinaciones de factores, como una variable de “precio más bajo”.
3.3 La previsión de la demanda es solo una parte de la planificación y optimización del retail
Para finalizar, deberíamos tener en mente que, aunque la previsión de la demanda del retail es esencial, incluso grandes cantidades de pronósticos no sirven para nada si no se usan de forma inteligente para dirigir las decisiones de negocio. Al gestionar productos de baja rotación, por ejemplo, la precisión de pronóstico es mucho menos importante para la rentabilidad que la optimización del reabastecimiento y los espacios, que impulsarán flujos de productos bien equilibrados de baja rotación en toda la cadena de suministro. Los retailers más avanzados están aplicando la inteligencia artificial en sus principales procesos de planificación – demanda, operaciones y merchandising – para mejorar la rentabilidad y sostenibilidad.
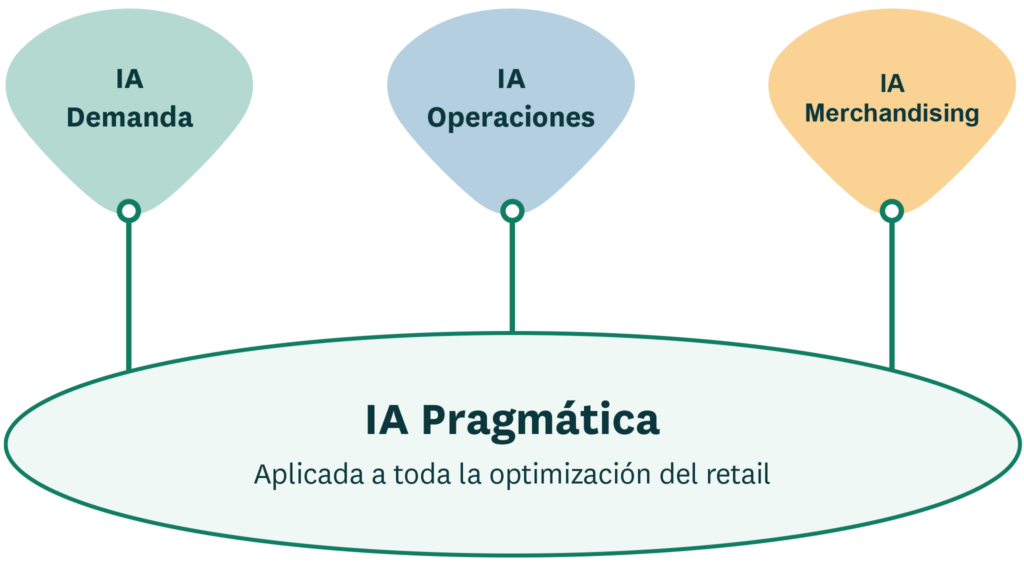
Imagen 11: La previsión de la demanda es sólo un área de aplicación de la IA en retail. Los retailers más avanzados aplican también la IA al merchandising y a operaciones para mejorar la rentabilidad y la sostenibilidad.
Si bien la implantación de los pronósticos de demanda basados en machine learning ofrece una base sólida para empezar con la IA aplicada, el retailer no debería conformarse solo con esto. La IA ha demostrado ya su valor para abordar una amplia variedad de los retos de planificación típicos del retail: desde la optimización de las jornadas laborales a una reposición de los productos más efectiva en las tiendas y una optimización de los descuentos automatizada y de más impacto. Con la aplicación de la IA pragmática en todos los procesos principales del retail se obtendrán resultados de forma sorprendentemente fácil y con grandes beneficios rápidamente.
Autor




