How accurate promotion forecasting and replenishment drive retail success
Jan 9, 2025 • 10 min
Promotions are essential to retail success, but too often, poor execution delivers poor results. Inaccurate promotional forecasts can result in either low availability and lost sales or, if you overestimate the demand impact of a promotion, costly spoilage and markdown losses down the road. Retailers can avoid these pain points by focusing on improvements to their retail promotion planning.
Promotional forecasting and replenishment don’t have to be this difficult. Modern technology has transformed retail promotion management by eliminating guesswork and making it possible to execute promotions with a high level of accuracy and automation. Companies must adopt smarter forecasting methods to achieve greater efficiency — and they’ll need the right technological capabilities to do it.
What is promotion forecasting?
Promotion forecasting is the practice of predicting how marketing campaigns, discounts, and promotions affect product demand. It analyzes historical sales data, market trends, and consumer behavior to estimate future sales volumes. Understanding these patterns helps businesses improve inventory management, pricing strategies, and marketing efforts for more effective promotions.
This practice supports supply chain operations and ensures product availability. Accurate forecasts reduce the risk of stockouts or overstock, leading to higher customer satisfaction and loyalty. They also help allocate resources more efficiently, plan production schedules, and coordinate with suppliers. Companies that integrate promotion forecasting gain an edge in navigating market fluctuations and sustaining profitability.
Why is accurate promotion forecasting important?
Research conducted by RELEX in partnership with Incisiv revealed that promotions drove $1 trillion in sales in 2023. Economic uncertainty, inflation, and shifts in shopper behavior are making promotions a more essential tool for retailers to attract and retain shoppers than ever. In the same report, 87% of retailers cited anticipating maintaining or increasing promotional efforts in the future.
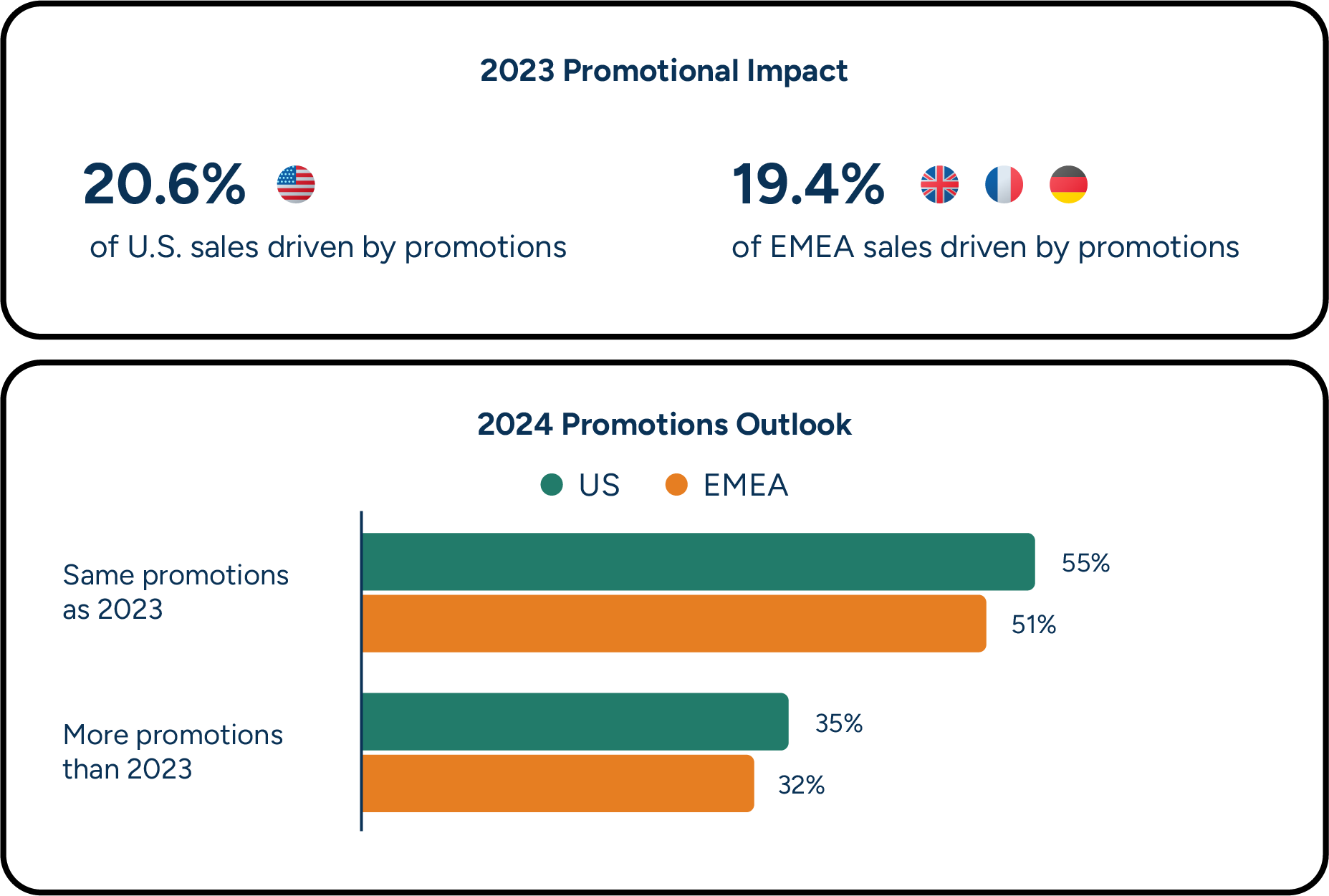
Unfortunately, most retailers’ promotion forecasting and replenishment processes are disjointed and unnecessarily complicated. Category managers rely on a combination of past experience and supplier projections to plan promotions, then demand planners must calculate the predicted promotional sales uplift.
Without a centralized system, though, individual stores are forced to manually place store orders for promoted products to meet demand, while supply planners must estimate how much stores will order and what that means for distribution center (DC) inventory and purchasing requirements. Too often, all of this happens in silos, with no shared data or plans.
4 keys to better retail promotion forecasting and replenishment
Accurate promotion forecasting, supported by robust demand planning, lays the groundwork for better margins, improved customer experiences, and stronger supply chain efficiency. Yet, achieving such accuracy requires more than just modern tools or guesswork. Forward-thinking retailers should employ four key practices to streamline their promotional forecasting and replenishment.
1. Drive accurate, automated retail promotion execution with rich data
With access to timely, accurate master data, modern promotion planning solutions can automate an enormous amount of work that has traditionally been executed by hand in cumbersome spreadsheets. These solutions can calculate high quality demand forecasts and inventory requirements for both normal and promoted stock. The richer the master data available, the more accurate these calculations will be.
The system should have access to a wide range of promotion data — the more, the better. This data includes promotion type (such as whether it’s a multi-buy), price change, advertising strategy, potential changes to in-store displays, and so on. With this data in place, the system can accurately automate the process of predicting promotional uplift per store or fulfillment channel.
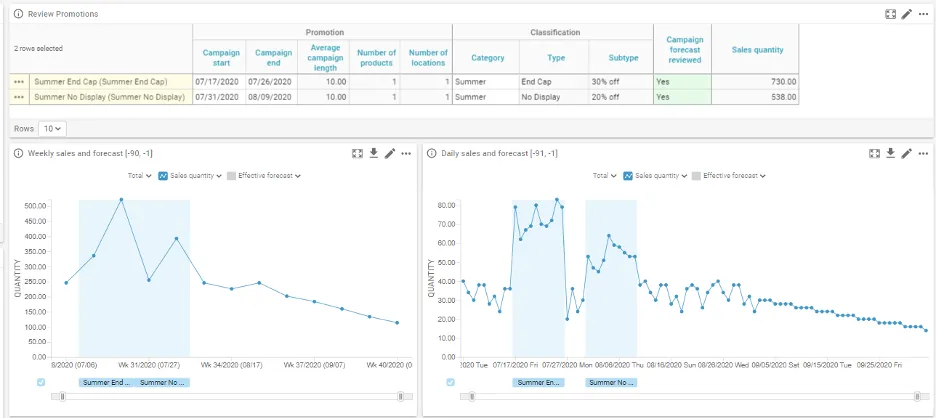
The benefits of improved promotional forecast accuracy carry forward. Enhanced accuracy drives optimized replenishment, which in turn drives higher availability and less risk of excess stock. But it all begins with data, the foundation of any accurate forecast.
2. Improve retail promotion forecasting accuracy with machine learning
Legacy tech stacks are crumbling under the weight of today’s datasets, and increasing complexity only compounds the issue. 37% of retailers surveyed across the U.S., U.K., France and Germany are still using spreadsheets as their core platform for managing promotions. However, modern advancements in machine learning technology have significantly improved promotional forecasting capabilities and accuracy.
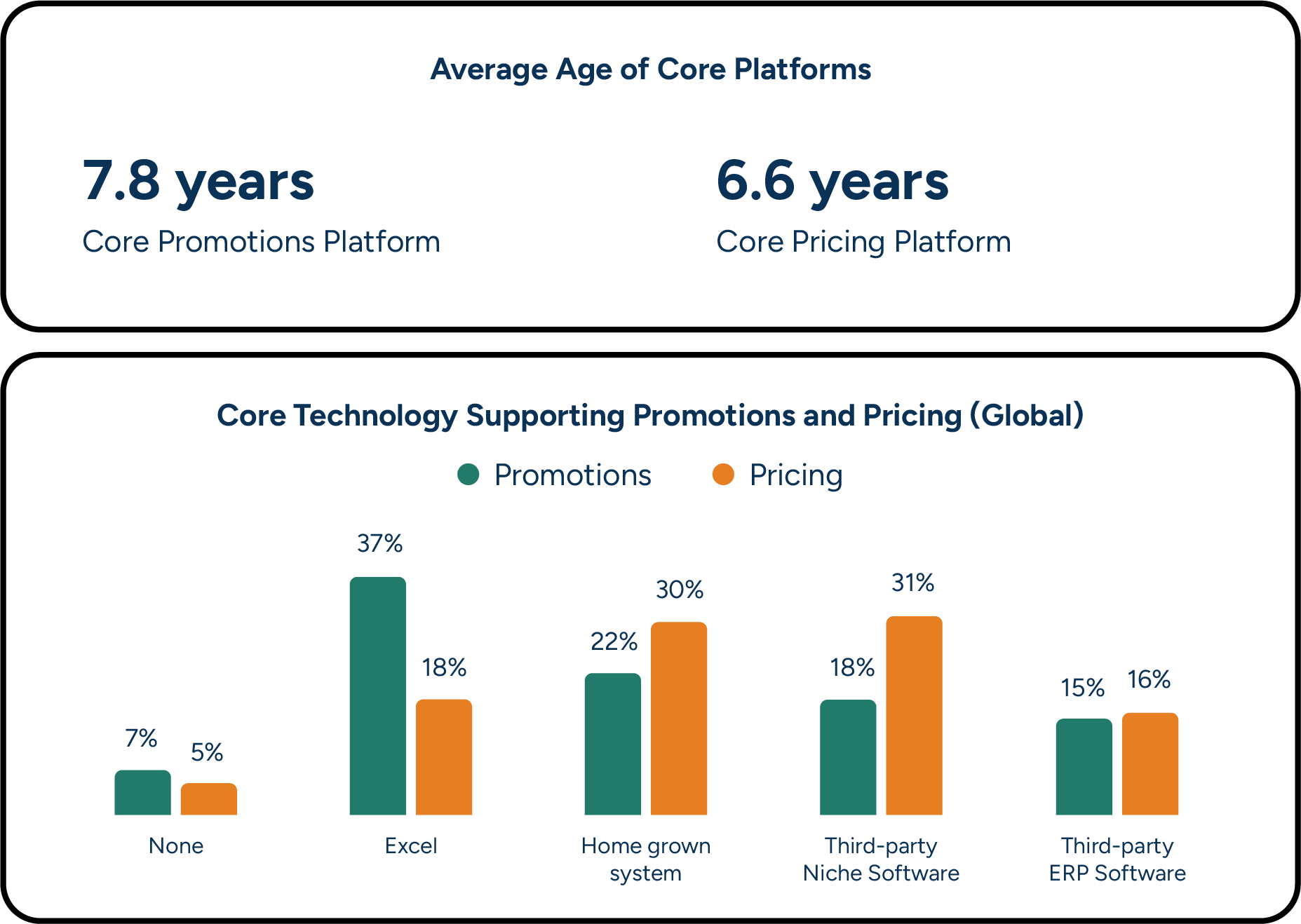
Machine learning algorithms can quickly analyze enormous, retail-scale data sets. They can automate highly accurate, granular forecasting for both stores and online channels, as well as channel forecasts for CPGs, without an outsize time investment from a planning team working in spreadsheets. Furthermore, machine learning-driven forecasts can incorporate more data on demand-influencing factors than any planning team could humanly manage. This data includes recurring demand patterns such as seasonality and weekday variation, external influences like weather changes or competitor activities, and the retailer’s own business decisions—including promotions.
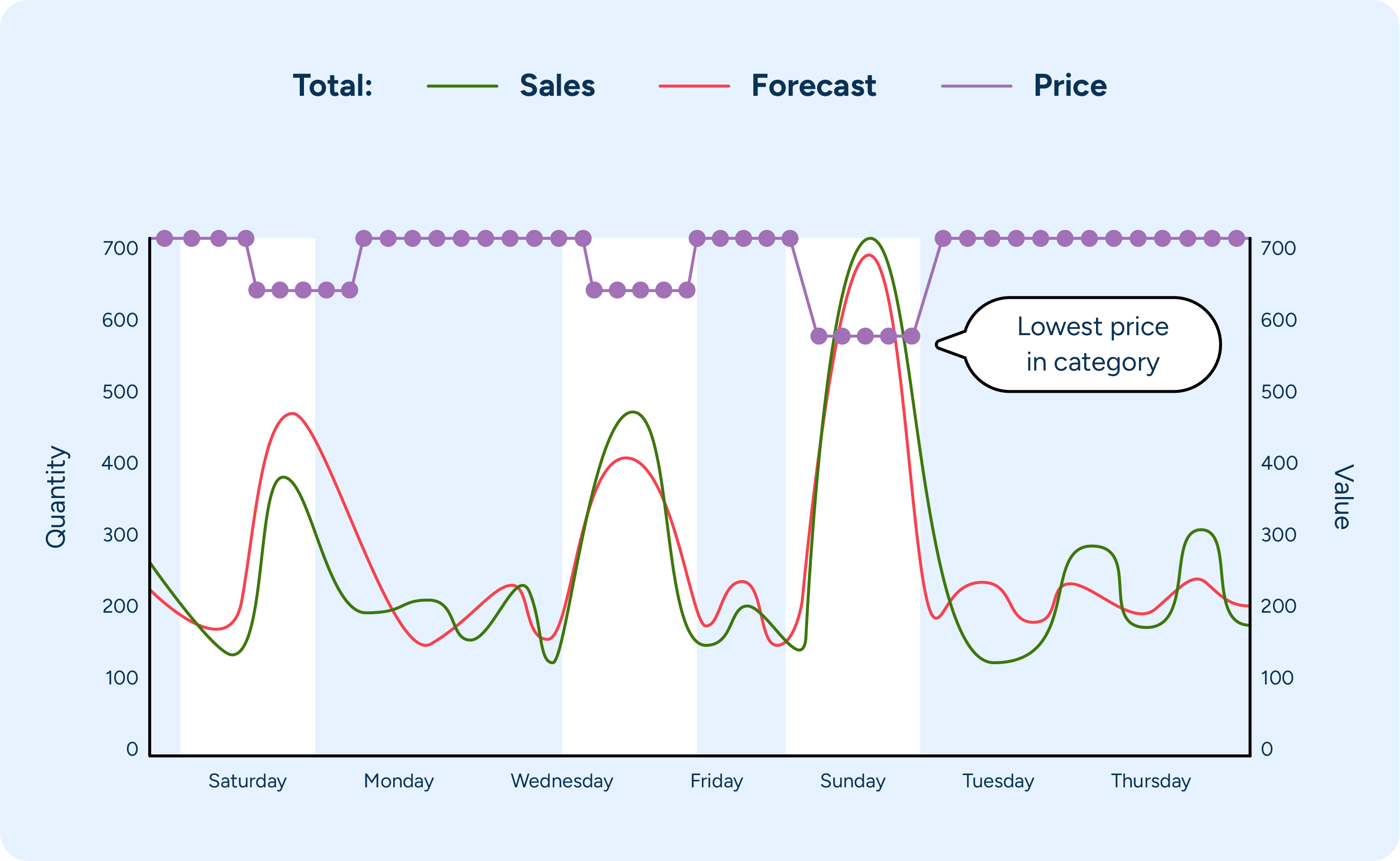
By analyzing all these factors within the same model, the system can identify not only how individual factors will influence promotional forecasts but also how those factors will interact with one another.
For example, there may be a planned promotion coming up for the HappyCow brand’s lean organic ground beef. Last summer, it was on promotion at a discount of 25% and was displayed on an end cap. This time, it’s winter, and the planning team is considering a 30% discount while maintaining the same display position. With machine learning, the system can easily take into account the time of year, the increased discount, and the display position to determine how these factors, when taken together, will impact sales.
Machine learning can also determine secondary impacts like cannibalization, which becomes a concern, especially when dealing with short shelf-life products. Consider a grocer who carries two brands of lean organic ground beef — HappyCow and GreenBeef — but runs a promotion only on HappyCow. The solution can automatically draw from master data to determine the promotion’s impact not only on HappyCow demand but on GreenBeef demand as well.
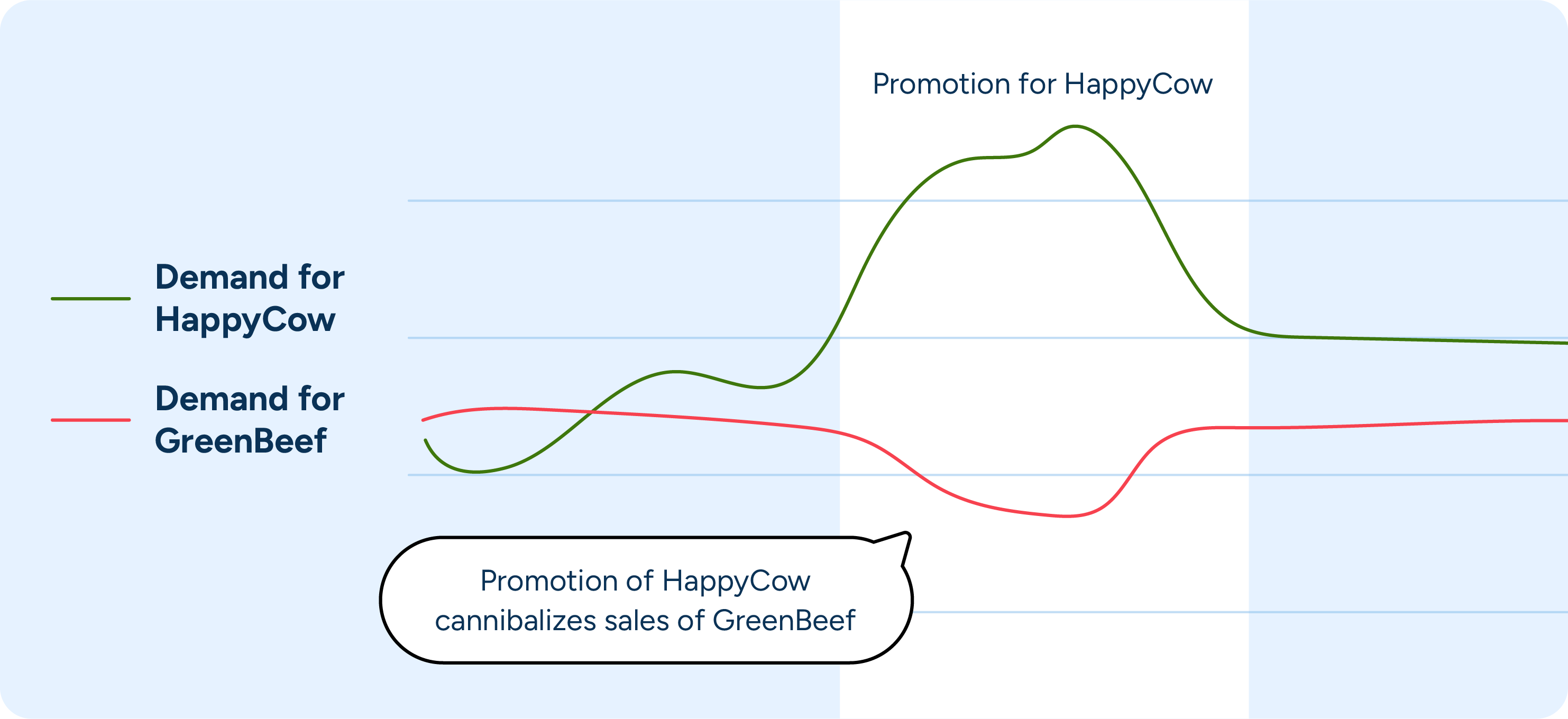
It can then automatically decrease order amounts of GreenBeef (preventing spoilage) while increasing HappyCow orders (ensuring availability) throughout the duration of the promotion period. Ultimately, the grocer avoids over- or under-ordering either brand, minimizing both waste and disappointed customers.
While human intervention will always be needed for some aspects of promotional planning, machine learning alleviates a great deal of the manual work that was required in the past. When planners have access to automated, data-based, trustworthy forecasts, they can focus on the situations the system flags as exceptional, such as novel promotion types that require more hands-on management.
3. Automate store replenishment effectively with accurate retail promotion forecasts
The benefits of an accurate promotional forecast go beyond developing a higher degree of certainty around the amount of inventory a retailer is likely to sell. An accurate day-product-store level demand forecast also enables accurate and automated store replenishment, which is of particular importance during promotional periods.
Planners can configure their supply chain solution to define how early promoted inventory should be delivered to stores and what proportion of the promotional demand should be allocated to that early delivery. This gives store staff sufficient lead time to build their in-store displays and stock shelves, ensuring availability during the high-demand promotion period. The system then uses information on local sales, demand forecasts, available stock in distribution centers, distribution center capacity, and other factors to fulfill the remaining demand following standard replenishment cycles.
To improve automation, retailers can develop templates for different types of stores and promotions to fit their business characteristics and goals. These templates are used to quickly implement configurations that automatically calculate initial store orders and subsequent replenishment orders — even ramping down toward the end of the promotion period if desired.
4. Drive retail promotion success with end-to-end inventory management
Retailers who bring forecasting and replenishment planning for stores, online channels, and distribution centers into a centralized system ensure full supply chain visibility. For example, combining elements like forecasted customer demand per store, fulfillment channel, day, and product with replenishment schedules and batch sizes can help to more accurately calculate end-to-end inventory needs. Whether running promotions in stores or through multiple sales channels, retailers can leverage this supply chain visibility into improved promotion management.
In an integrated supply chain, DC forecasts are based on store order projections, which ensures that the demand impact of any planned promotions is made immediately visible throughout the supply chain (Figure 5). This helps planners secure the right amount of inventory for the right locations on the right dates.
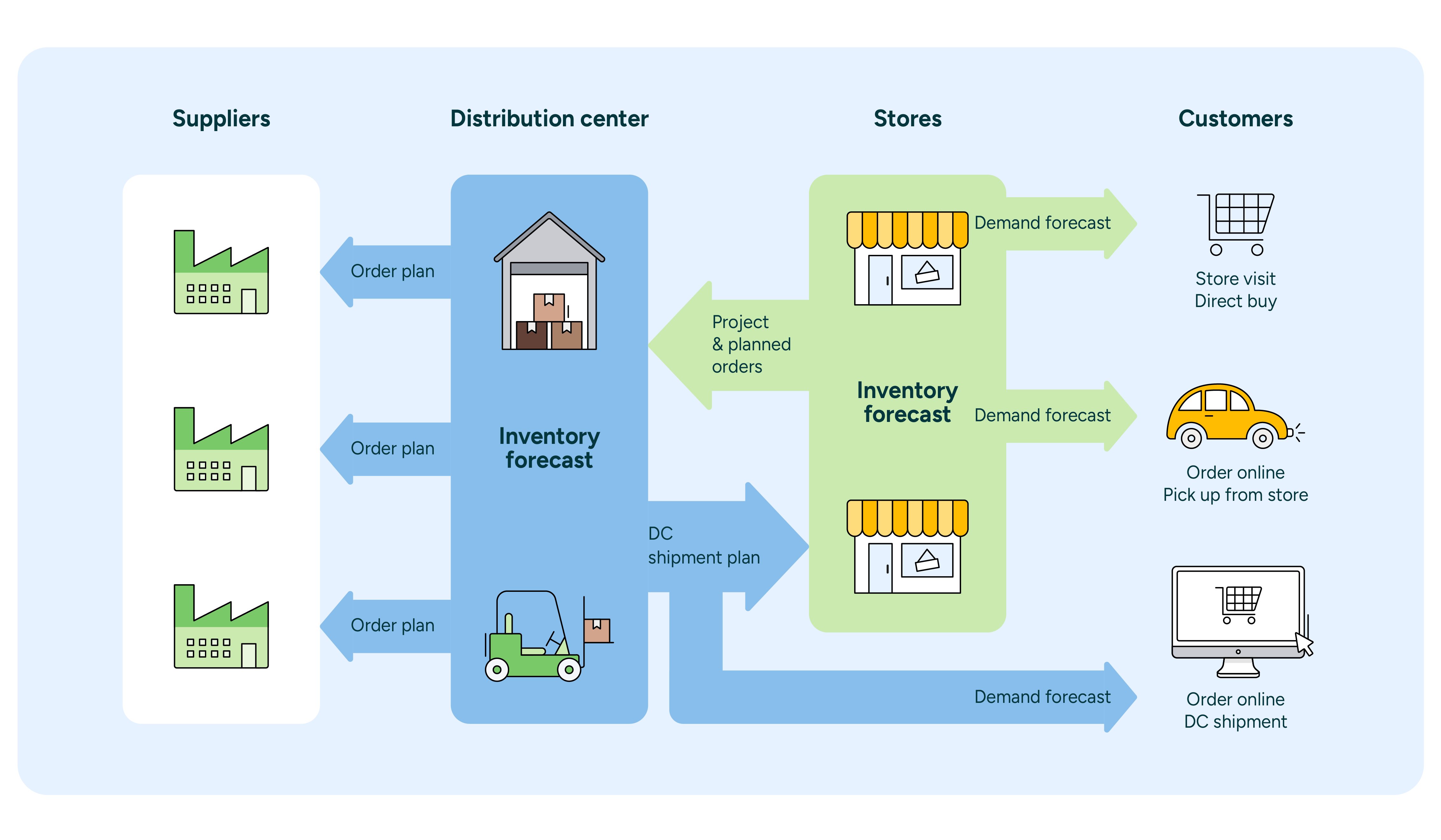
Omnichannel retailers who run promotions both in stores and online face an additional layer of complexity in promotional forecasting. However, they can streamline that complexity with an end-to-end system that also maintains separate forecasts by channel. Inventory needs for each channel during promotional periods will be incorporated into distribution centers’ normal forecasting processes, untangling a large amount of information through increased visibility and high levels of automation.
This kind of visibility and integration can also ensure online availability through virtual ringfencing. Virtual ringfencing uses online demand forecasts to automatically reserve inventory in your distribution centers, preventing store pre-orders from claiming too much stock. With access to channel-level data on promotional sales, the system can also automatically adjust or remove ringfencing rules as needed.
End-to-end inventory management also benefits the operative buying teams responsible for efficiently exploiting rebates to improve gross margins. In theory, smart buying when suppliers offer temporary price reductions for promoted items is quite straightforward: retailers should order less product just before a temporary price reduction and stock up when the price is low.
However, to get the greatest benefit from price changes, retailers also need to factor in their inventory carrying cost, time their orders correctly relative to when the price is changing, and potentially split the investment buy (the additional quantity above what’s needed to meet demand) into several orders. Storage space availability and product shelf-life also need to be factored in.
To optimize forward buys, a planning solution should consider these restrictions alongside time-dependent trade promotion data. Supply chain integration gives the solution access to all the information it needs to automate calculations for when and in what quantities orders should be placed.
Ultimately, end-to-end inventory management enables retailers to plan promotions once and then automate their execution based on forecasted demand and inventory requirements throughout their supply chain.
Effective retail promotions are within reach
Even with all these moving pieces in play, today’s technology makes effective promotion management more achievable than ever before. With consistent access to high-quality data, modern supply chain solutions can improve promotional forecast accuracy by 15%, improving store replenishment and inventory optimization throughout the supply chain.
Reitan Convenience Sweden (RCS) is a leading company in the Swedish convenience store industry with over 400 stores and are well-known for their Pressbyrån and 7-Eleven brands. Henrik Carlsson, Director of IT and Digitalization, and Martina Molander, Category and Purchasing Manager at Reitan sat down to share how RELEX is helping them optimize their promotion planning and execution.
The results can be significant. German drugstore chain Rossmann, for example, saw a 30% reduction in inventory levels for promoted items while improving availability, with a 10% reduction in stock-outs on promoted items.

Retailers who target improvements to promotional forecasting and replenishment typically also see benefits like more efficient delivery flows and optimized capacity.
As retailers compete for consumer attention and customers embrace the convenience of omnichannel shopping, retail promotions are only growing in importance and complexity. Fortunately, developments in supply chain optimization technology put retailers in a strong position to automate and improve their promotional planning and execution.
Written by

Related Articles

Navigating tariff volatility: Smart pricing strategies when costs get complicated
Learn how leading retailers use data-driven pricing strategies to navigate tariff changes while protecting margins and maintaining customer loyalty. Expert insights and proven approaches.

Customer video: Vallarta Supermarkets
David Hinojosa, COO at Vallarta Supermarkets, shares how RELEX is helping them transform their retail operations.

Retail pricing strategies: How AI keeps retailers profitable and popular
Discover how AI-driven pricing solutions help retailers optimize pricing strategies, protect margins, and boost customer satisfaction.