Big data – Big talk or big results?
Aug 28, 2013 • 10 min
Businesses, business analysts and commentators have been talking about what they call ‘Big Data’ for at least a decade now and the term is being applied to pretty much anything.
Precise definitions are hard to come by. The McKinsey Global Institute (MGI), amongst others, has settled for: ‘“Big data” refers to datasets whose size is beyond the ability of typical database software tools to capture, store, manage, and analyze;’ a definition so broad as to be almost meaningless.
If big data were simply about computational power then a reasonable response would be to wait for your CFO to budget for more server space and for Big Data to come to you. However more is not always better as any adult who gives a six year old unlimited quantities of ice cream will know.
Forget the hype for a moment. Big Data isn’t a magic bullet. But there are some real benefits to be had and not just in the most talked-up arenas of marketing and on-line business. There are also impressive gains to be made in traditional operations, such as supply chain management, which can be had from:
1) increased data transparency and faster access to data and calculations
2) faster and more detailed performance monitoring and exception identification
3) faster and more accurate decision-making using automated algorithms, as well as
4) faster and more accurate analyses
According to The McKinsey Global Institute applying big data solutions to supply chain management can add between 5% and 35% to operating margins.
Moreover the technology to process and analyse big data, technology which makes big data relevant and useful to your business, is already here. And, if you’re happy to sidestep the big legacy system providers and the premium you pay them for their “brand value”, then the technology you need is surprisingly affordable, even for Tier 2 and smaller companies.
Building Big Data Power With “RELEX Technology”
Retail has always generated information aplenty and in the digital era this data has multiplied and become increasingly accessible. RELEX’s technology uses advanced algorithms and analytics that can turn this data into a powerful resource providing better forecasting, dynamic snapshots of a business in real-time and instantaneous illustrations of the impact of supply chain decisions.
The key elements of RELEX’s technology are illustrated in the figure below.
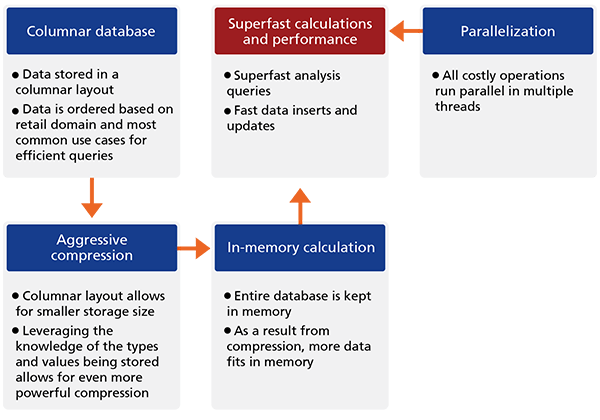
Columnar Database
A database table essentially works in two dimensions: rows and columns. Computer memory, such as a hard drive, only has one dimension – much in the way that old fashioned audio cassettes were linear. This means that all data has to be serialized into a one-dimensional data stream before it can be stored in memory or on disk.
There are two principal alternatives for serializing a database table into a one-dimensional data stream: row layout and column layout. Most traditional relational databases use the row layout.
Row layout means that database table rows are written one by one in a stream of information; each row in turn in its entirety with all its columns. For applications that typically need to process all or most columns of each row at a time, this is good. For example, if a table records personal data, the application might always need the name, gender, year of birth, address, etc. for each person processed. When the data representing a person is found in memory or disk, all this data is available next to each other.
In column layout, each column is written to the data stream in turn; so first all rows for column 1, then all rows for column 2, and so forth. This is typically ideal for analysis applications, where a table might have tens or even hundreds of columns, but where only a few of them generally need to be read at a time, but those that do need to be read are read across a large number of rows. If row layout is used – keeping the tape analogy in mind – reading a single column for every row means we have to scan through every column of every row. If column layout is used instead, it is possible to fetch the data for only a single column without wasting time scanning through the data in all the other columns.
Aggressive Compression
Another benefit of using column layout is that values of the same data type are now adjacent in memory or on disk, which makes compressing the data more efficient. In row layout, adjacent values may represent different data types (for example, person’s name and year of birth), which makes compression less efficient.
In addition, most of RELEX’s data consists of sales, orders, deliveries, inventory balances, forecasts etc. A huge percentage of the values are small integral numbers, and many of the values do not actually change that often. One example would be the inventory balance of a slow moving product, which remains the same for several days. Leveraging the knowledge of the types and values being stored allows for even more powerful compression. The compression factor is around 10 times that of row-based layout. In other words, a RELEX customer database that might require 100 GB storage in a typical relational database takes up around 10 GB in a RELEX system. That smaller storage size also translates into improved performance.
In-memory Calculation
This compression makes it possible to run all of the data in-memory. Essentially this means that data is queried when it’s within the computer’s random access memory (RAM), as opposed to being read on and off physical disks. This again vastly shortens query response times and results in far better performance.
Parallelization
RELEX’s multi-threaded internal architecture allows all time-consuming operations to be run in parallel on multiple threads which, again, improves performance. Loading data, evaluating queries and performing calculations is speeded up by using multiple processors at the same time.
Development of RELEX’s Solution
RELEX has an integrated, custom-built database engine. This is a very unusual solution in our sector. Since the rise of the relational databases in the 1970s, the prevalent model in enterprise software has been to offer a database and an application as two separate pieces of software, most commonly from different vendors. The database acts as a server that the application software can connect to. To understand why RELEX has taken the unconventional approach of writing a custom database engine, it’s necessary to first understand the limitations of the client-server model for databases.
Limitations of Client-server Model for Databases
These limitations are best illustrated via an analogy. Imagine that a database server is like the archive department of a big company, and that the application software is the business development department. Business development needs to use the information in the archive. These two departments are located in two separate buildings. People working in the business development department are not allowed into the archive department building. Instead, to access the information in the archive, they need to write letters explaining what they need. The workers in the archive department read these letters, find the necessary information in the archive, and send the results back.
The archive workers don’t understand anything about the data in the archive – to them it’s just numbers. This means the business development people need to be absolutely explicit in their information requests. You could imagine that a worker in the business development department might write a letter to the archive saying: ”Please go through all records in cabinet X, and calculate the total sum of Y.
But please ignore all records for which A is Z.” In the database world, these letters asking for information are called queries. In relational databases, they are usually expressed in SQL, a specialist programming language.
The replies sent back by the archive workers have to be either compact summaries of some part of data in the archives (such as sums, averages, minimums or maximums over some set of records) or copies of a limited number of records. We should assume that the archive contains such vast numbers of records that it’s not feasible to send out copies of all of it. Thus the business development personnel need to formulate their data requests carefully to be able to obtain the answers they need.
Extensions to SQL
To develop the analogy a little, imagine that there are sometimes cases in which the business development workers need to do some very complicated calculations on the data in the archive, and the complexity is such that it cannot adequately be explained in the data request letters. So instead of letting the archive workers do the calculations and send back only the results, they need to ask copies of all the necessary records to be sent to them, so they can carry out the computations themselves.
Database servers typically allow the limitations of the SQL language to be circumvented via extensions mechanisms, such as user-defined functions and stored procedures. These are often expressed in a vendor-specific extension language. The end result is that some of the logic that would otherwise reside in the application software is implemented inside the database server, so that the processing can be executed closer to the data and less information needs to be sent back to the application. In the archive department analogy, this would be something akin to training the archive workers to understand more complicated data requests, perhaps arming them with chalkboards or notebooks to write intermediate results on.
User-defined functions and stored procedures have the potential to greatly improve the overall efficiency of software using a database server, but even they have their limitations. The custom languages used for them are no match for a fully-fledged programming language.
Also the possible data access patterns are limited. In the archive department analogy, you might imagine a data request stating ”oh, and if the record in question represents a product that replaced another product in the assortment, please go to cabinet Q and fetch the corresponding record F, but only if…”. So there are always parts in the business process that cannot be conveniently expressed via these extension mechanisms.
Eliminating the Bottleneck
Next imagine that we do something radical: Give the business development workers full access to the archives. We might go as far as to give those workers desks inside the archive building so they can work there all the time. Now anytime they need to get some information from the archive cabinets, they can just get up and go find what they need. No more writing detailed data requests in a constrained language, and no more copying and sending results back.
This is essentially how RELEX’s software works. The database and the application is a single, seamless piece of software. Any performance-critical business process can always be implemented at the lowest possible level, pushing the data flow through a digital ‘fire hose’ instead of a ‘straw’. Moreover, even the data storage can be organized in such a way as to best answer any business questions with the highest possible performance.
If this model of an integrated database offers such tremendous benefits, why isn’t every software company taking the same approach? One reason may be that developing a custom database engine is both very challenging and time-consuming. In most cases, the benefits simply don’t outweigh the risk and the amount of work needed – an off-the-shelf general-purpose database server can provide ‘good enough’ performance.
So when we talk about the superior levels of performance that RELEX’s systems can deliver, what exactly do we mean? Let us have a look at some figures: for example with RELEX it’s possible to…
- calculate around 5 billion forecasts an hour,
- upload approximately 1 billion transaction an hour,
- sort one million products according to their shelf availability, from best to worse or vice versa, in one second, and
- conduct a query, e.g. find all products that have more than 100 EUR in sales for the last 30 days, and export it as a csv-file with 1 million rows in one minute.
Is RELEX’s Technology Unique?
There are similar components in other big data solutions. For example, many of the major data warehousing vendors are reaping the benefits of columnar technology. HP Vertica, Sybase and Teradata columnar are just a few examples. There are also many purpose-built solutions like SAP HANA and Oracle Exadata that integrate database, storage and processing. What is unique about RELEX’s solution is that it was deliberately designed from the start with the intended application area, most common use cases and profile of our typical customer’s data uppermost in our minds.
Many of the companies offering big data solutions concentrate on the technology and overlook the need to ensure it serves the requirements of real business people. The result is that we have many elegant technical solutions in search of a problem. Usually, business people want straightforward solutions to their problems, not ‘general development environments’ that may, or may not, lead to them solving their problems or technology that requires they develop a solution themselves. We offer our customers solutions that actually help them make their business perform better, and help them overcome particular challenges related to, for example, inventory management, demand forecasting and assortment management.
Big Data, Big Conclusions
Big Data offers a real opportunity. As with many technological advances a lot of the big decisions aren’t tech decisions but management decisions. You need to know what you want out of it. Sometimes you know that better at the end of a project than at the beginning. That’s life.
At RELEX we offer real life solutions. Our systems have been designed from their inception to handle vast data flows and that makes dealing with big data intuitive, straightforward and useful.
Not only that but the way we work with you to implement our systems assumes that you won’t have all the answers when the project begins. Not only does the flexibility built into our systems allow us to modify them at every turn as we implement them, it also allows you to modify them yourself as you roll them out.
The technology that allows you to master big data and make it work for you already exists. What’s more RELEX systems change as you change, grow as you grow. And, with RELEX customers typically seeing a full return on their investment in our systems just three months after full roll-out, the decision to move forward should be an easy one.”
Written by

Related Articles

Touchless planning for AI-driven supply chain excellence
Learn how RELEX's AI-powered touchless planning automates complex manufacturing tasks, integrates demand and supply planning, and builds operational resilience in volatile markets.

Touchless planning: A manufacturer’s guide to AI-driven supply chain excellence
Discover how touchless planning transforms manufacturing with AI-driven solutions and why automated forecasting is now essential for competitive advantage.
Beyond resilience: Building the anti-fragile supply chain
Join supply chain experts from RELEX Solutions as they explore the current landscape of supply chain disruptions, focusing on building anti-fragility through AI-enabled technology.