
Retail is detail at large scale
The old adage is common but true: “Retail is detail at large scale.” To ensure smooth operations and high margins, large retailers must stay on top of tens of millions of goods flows every day. At the center of this storm of planning activity stands the demand forecast.
A highly accurate demand forecast is the only way retailers can predict which goods are needed for each store location and channel on any given day — which, in turn, is the only way to ensure high availability for customers while maintaining minimal stock risk. A reliable forecast leveraged across retail operations can also support capacity management, ensure the right amount of staff in stores and distribution centers, or help buyers manage the complexities of long lead-time purchasing.
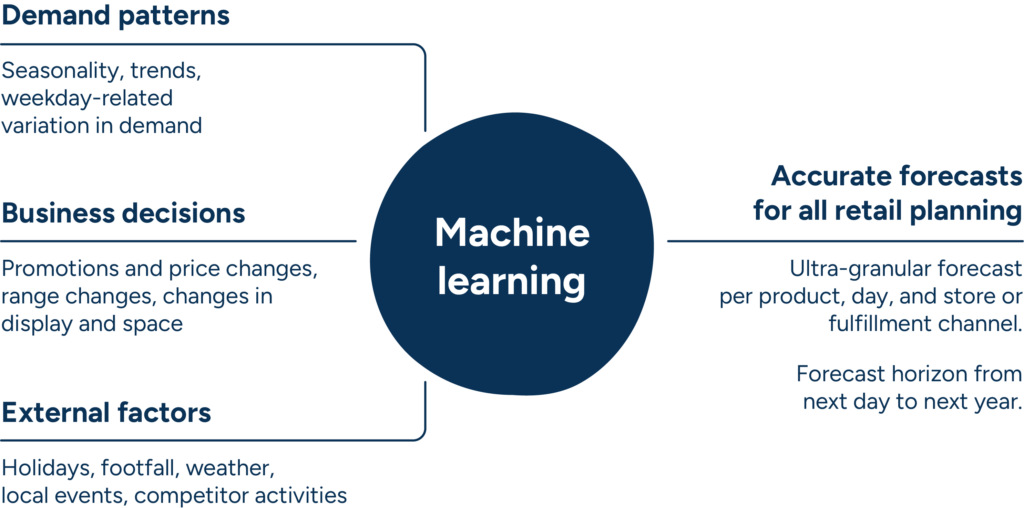
Generating an accurate forecast is actually quite simple under stable conditions, but we all know too well that retail is inherently dynamic, with hundreds of factors impacting demand on a continuous basis. Every day, retail demand planners struggle to consider an immense number of variables, including:
- Recurring variations in baseline demand, such as weekday-related and seasonal variations.
- Internal business decisions designed to capture consumer attention and provide a competitive edge, such as promotions, price adjustments, or changes to in-store displays.
- External factors, such as local events, changes in a store’s neighborhood or competitive situation, or even the weather.
With this much data, no human planner could take the full range of potential factors into consideration. However, machine learning makes it possible to consider their impact at a detailed level, by individual store or fulfillment channel. It’s not surprising, then, that so many retailers today are transitioning their technology strategies toward machine learning-based demand forecasting.
1. What is machine learning, and why should retailers adopt it now?
Machine learning gives a system the ability to learn automatically and improve its recommendations using data alone, with no additional programming needed. Because retailers generate enormous amounts of data, machine learning technology quickly proves its value. When a machine learning system is fed data — the more, the better — it searches for patterns. Going forward, it can use the patterns it identifies within the data to make better decisions.
Machine learning makes it possible to incorporate the wide range of factors and relationships that impact demand on a daily basis into your retail forecasts. This is enormously valuable, as just weather data alone can consist of hundreds of different factors that can potentially impact demand. Machine learning algorithms automatically generate continuously improving models using only the data you provide them, whether from your business or from external data streams. The primary benefit is that such a system can process retail-scale data sets from a variety of sources, all without human labor.
Of course, machine learning algorithms are not new — they’ve been around for decades. But never before have they been able to access as much data or data-processing power as is available today.
2. Machine learning tackles retail’s demand forecasting challenges
Machine learning is an extremely powerful tool in the data-rich retail environment. It should be leveraged in any context where data can be used to anticipate or explain changes in demand. In some instances, it can even fill in the gaps where the data is lacking.
2.1 Complex phenomena that impact demand
Time-series modeling is a tried-and-true approach that can deliver good forecasts for recurring patterns, such as weekday-related or seasonal changes in demand. In our experience, though, machine learning-based demand forecasting consistently delivers a level of forecasting accuracy that is at least on par with and usually even higher than time-series modeling. Whereas time-series models simply apply past patterns to future demand, machine learning goes a step further by trying to define the actual relationship between variables (such as weekdays) and their associated demand patterns.
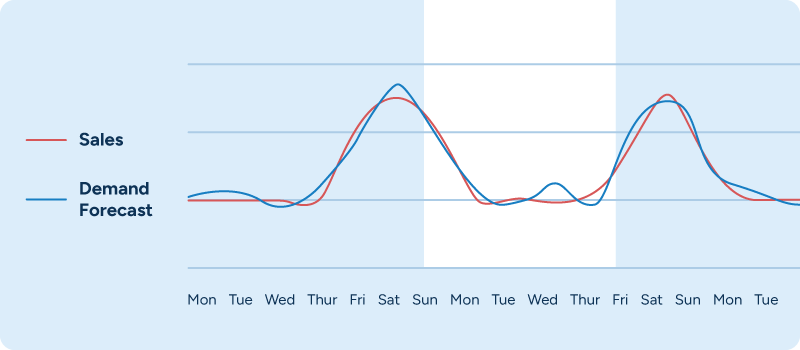
Machine learning also streamlines and simplifies retail demand forecasting. When using time-series models, retailers must manipulate the resulting baseline sales forecast to accommodate the impact of, for example, upcoming promotions or price changes. Machine learning, on the other hand, automatically takes all these factors into consideration.
In addition to taking an abundance of factors into account, machine learning also makes it possible to capture the impact when multiple factors interact — for example, weather and day of the week. Warm, sunny weather can drive a much bigger demand increase for barbecue products when it coincides with a weekend.
2.2 Price changes, promotions, and other business decisions impacting demand
Your own business decisions as a retailer are also an important source of demand variation, from promotions and price changes to adjustments in how products are displayed throughout your stores. Yet, despite the fact that retailers typically plan and control these changes themselves, many in the industry are unable to accurately predict their impact.
Machine learning allows retailers to accurately model a product’s price elasticity, i.e., how strongly a price change will affect that product’s demand. This capability is highly valuable as part of promotion forecasting, as well as when optimizing markdown prices to clear out stock before an assortment change or the end of a season. Furthermore, retailers must regularly adjust consumer prices to reflect supplier prices and other changes in their cost base.
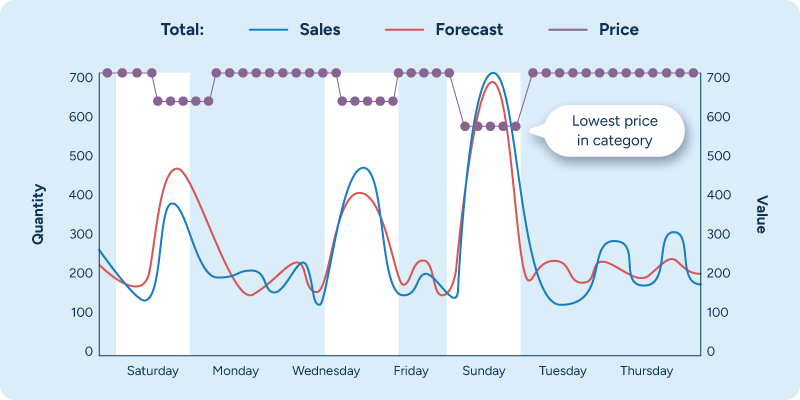
Price elasticity alone, however, does not capture the full impact of price changes. A product’s pricing in relation to alternate products within the same category often has a large impact as well. In many categories, the product with the lowest price captures a disproportionally large share of demand. Machine learning-based demand forecasting makes it quite straightforward to consider a product’s price position, as shown in Figure 3 below.
In a 2020 study of North American grocers, 70% of respondents indicated that they could not take all the relevant aspects of a promotion—such as price, promotion type, or in-store display — into consideration when forecasting promotional uplifts. But they wish they could.
Here, too, machine learning can help. Using machine learning-based demand prediction, retailers are able to accurately predict the impact of promotions by taking into consideration factors including, but by no means limited to:
- Promotion type, such as price reduction or multi-buy.
- Marketing activities, such as circular ads or in-store signage.
- Products’ price reductions.
- In-store display, such as presenting the promoted product in an endcap or on a table.

Sales cannibalization, the phenomenon in which one product’s promotional uplift causes a reduction in sales for other products within that category, is quite common and must also be accounted for in forecasts, especially for fresh products. For example, if a supermarket carries two brands of lean organic ground beef — HappyCow and GreenBeef — they should expect that a promotion on the HappyCow product will cause more people to buy it. As a result, though, some of the demand for the GreenBeef product will shift to HappyCow. If the demand forecast for the GreenBeef product is not accurately lowered, the retailer is at high risk of overstocking, which will ultimately drive waste.
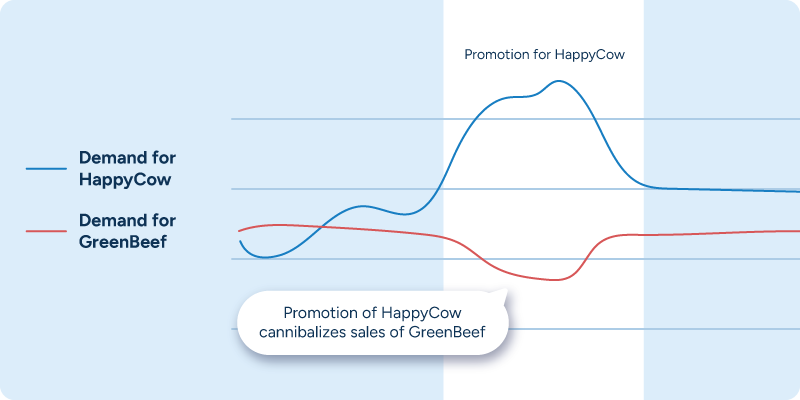
Manually adjusting the forecasts for all potentially cannibalized items is just not feasible in most retail contexts because the number of products to adjust is simply too high. The patterns are also typically quite specific to individual stores’ assortments and shopping patterns. This is where machine learning algorithms’ ability to automatically identify patterns and adjust forecasts accordingly adds enormous value.
On the other hand, a promotion for the HappyCow product will likely increase sales for some related products outside of the “ground beef” class in what’s known as the halo effect. Hamburger buns, for example, have an obvious and predictable correlation with ground beef.
Unfortunately, the impact can be so diffused across the assortment that identifying every impacted product becomes more or less impossible, even with machine learning. Shoppers might associate onions, potato chips, beer, watermelon, taco meal kits, salad fixings, oyster crackers, corn on the cob, Worcestershire sauce, soy sauce, and any number of other items with ground beef-based dishes. But even if forecasting systems can’t identify all possible halo relationships, they should still make it easy for planners to adjust forecasts for the relationships they know to exist.
2.3 Weather, local events, and other external factors impacting sales
External factors such as the weather, local concerts and games, and competitor price changes can have a significant impact on demand but are difficult to consider in forecasts without demand planning software to automate a large portion of the work. At a high level, the impact can be quite intuitive. On a warm day, you’ll likely see increased ice cream sales, whereas the rainy season will see demand increase for umbrellas, and so on.
When looking at a retailer’s entire assortment, though, the challenge gets more complicated. How can you effectively identify all products that react to the weather? Can you account for the full range of variables that comprise a “weather forecast”—temperature, sunshine, rainfall, and more? Will the weather-related impact of sunshine be stronger in summer than in winter? Or stronger on weekends than on workdays?
The use of weather data in demand forecasts is a prime example of the power of machine learning. Machine learning algorithms can automatically detect relationships between local weather variables and local sales. They can map these relationships on a more granular, localized level than any human endeavor could accomplish — and are also able to identify and act on less obvious relationships that human intuition or “common sense” might overlook.
When demand planners or store staff are asked to manually check weather forecasts to influence ordering decisions, they focus on securing supply for anticipated demand increases — pushing ice cream to stores during a heat wave, for example. Rarely, though, does anyone have time to adjust ice cream forecasts slightly downwards during rainy weeks or cold snaps in the summer. A planning team using machine learning doesn’t have to worry about adjustments like that, as their system can suggest them automatically.
In our experience, automatically considering weather effects in demand forecasts reduces forecast errors by between 5% and 15% on the product level for weather-sensitive products and by up to 40% on the product group and store levels.
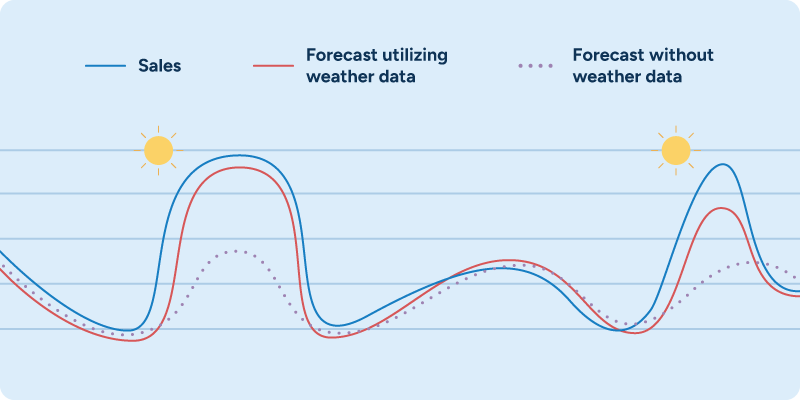
But weather data is by no means the only external data that could or should be incorporated in your retail demand forecasting. Any number of external data sources, such as past and future local events (e.g., football games or concerts), data on competitor prices, and human mobility data can be used to improve outcomes in the same way.
As an example, RELEX used machine learning to help WHSmith improve their understanding of how flight schedules impacted demand patterns at their airport locations. By feeding external data from airlines into the system, WHSmith improved their forecasts and were able to significantly reduce their fresh spoilage rates while improving availability.
2.4 Unknown factors impacting demand
Thus far, we’ve explored contexts in which the factors impacting demand — weekly and seasonal patterns, business decisions, and external factors — are readily identifiable. But machine learning can help adjust forecasts even in situations where the influencing factors, whether internal or external, are unknown.
Retail sectors often have abundant data. However, this data becomes scarcer or incomplete closer to the store and SKU levels. This is where replenishment decisions are frequently made. In brick-and-mortar retail, local events such as a competitor’s store opening or closing can significantly influence demand. Local environmental changes, such as construction interrupting access to roads or buildings, can impact short-term foot traffic and demand.
Unfortunately, data on these factors may not be recorded in any system. Sometimes, retailers’ internal decisions also go unrecorded, such as assortment changes, price changes, or adding a product to a special off-shelf display area in a store.
Fortunately, machine learning can help in these situations. Machine learning algorithms can tentatively place a “change point” in the forecasting model and then track subsequent data to either disprove or validate the hypothesis.
Level shift detection – detecting the points in time where the level of demand has changed significantly – allows forecasts to adapt quickly and automatically to new demand levels. This approach helps to improve estimates on things like promotions, events, and seasonality when the effect of unknown factors is controlled.
Level shift methodology also enables us to consider users’ external knowledge. Robustness is very important in large-scale retail demand forecasting, and we must avoid reacting to noise. However, when a user knows the cause behind an uptick in demand, a level shift can be added manually to make the model react immediately to that new level of demand.
Consider the example in Figure 7 below, in which a table display has been created in addition to the regular shelf space for a product. Though this change was not recorded in the master data, the system was easily able to track the demand impact as a factor of how the product was displayed in the store.

It’s important to remember that as algorithms become more complex, it’s essential to get the right data into the system. For example, recording when a product is and is not in the assortment is key to understanding its demand patterns.
Further, all the factors that influence demand that we’ve mentioned do not typically occur one at a time. It’s critical to be able to consider scenarios when a combination of things like weekdays, weather, promotions, and cannibalization happen at the same time. Only artificial intelligence (AI) and machine learning can handle such complex interactions between different demand influencers.
3. Make machine learning work for your retail demand planning
Although AI and machine learning technology have become mainstream, retailers should still keep some considerations in mind when determining how to utilize it in their business. Some considerations are specific to the retail context, whereas others — level of transparency, for example — are generic enough to apply to any situation that calls for computer-human teamwork.
3.1 Working with retail’s long-tail products
Retailers are right to prioritize forecasting concerns on fast-moving products, but slow movers constitute a substantial portion of inventory flows and present their own unique forecasting challenges. The limited granularity of data available for each product, store/channel, and demand-influencing factor for items that sell only a few units per day or week results in a high degree of random forecasting variation, making it difficult to discern patterns and relationships within the data noise.
Companies might have thousands of data points for fast-moving products but only tens to hundreds for long-tail products. This data scarcity makes it challenging to distinguish the effects of demand influencers like weather, price adjustments, display changes, seasonality, or competitor actions from apparent randomness. These insights are crucial for informed sourcing and replenishment strategies at distribution centers.
Data scarcity also risks “overfitting,” where too many variables or complexity overwhelms an algorithm and causes it to “learn” from noise rather than identifying the actual demand signals. These overfit models may appear accurate with training data but often falter when faced with new, unseen data, leading to erratic or “nervous” forecasts that overreact to minor changes in data.
The most effective method for overcoming low volumes and sparse data at the product-store/channel level involves data pooling. This technique requires the retailer to aggregate or “pool” the data they generate across various dimensions, including (but not limited to):
- Sales channels
- Product types
- Store locations
- Time periods
- Customer behavior, preferences, and demographics
- Promotional data
This “data pooling” strategy ensures that the collective insights contribute to a better understanding of demand influencers like promotions, weather, and seasonality, even with limited data per product-location. The pooling of this data enables machine learning algorithms to draw on a richer dataset, ensuring robustness to minimize the impact of long-tail demand variation on forecasting.
Data pooling also serves as a foundational technique for multilevel modeling, a statistical approach that requires aggregating information across hierarchical structures to bolster the model’s accuracy and robustness. Multilevel modeling facilitates a high degree of automation and robustness, enabling algorithms to adaptively choose the appropriate level of analysis — be it product-store, product-region, or product-chain — without manual intervention. This approach not only mitigates the risks associated with sparse data but also enhances the scalability and accuracy of demand forecasting for long-tail products.
3.2 Leverage human experience
Forecasting and replenishment automation is extremely useful in times of supply chain disruption, as it frees up large chunks of planner time. However, human planners are still essential in guiding the system when dealing with highly impactful, unusual events. Retailers in these situations should focus on more than just trying to make good predictions. They must also judge the business risk of upside and downside scenarios. Whether in exceptional times of disruption or more stable demand periods, human computer interaction is required in the form of actionable analytics.
Demand forecasts are never perfect, so there will always be situations in which planners need to dissect them. Forecast visualization tools allow planners to quickly grasp which factors influence, which fosters a deeper trust in the system’s capabilities. Planners can then trust the system to manage “business-as-usual” situations and focus instead on managing exceptional scenarios or manually adjusting forecast levels in response to rapidly changing conditions.
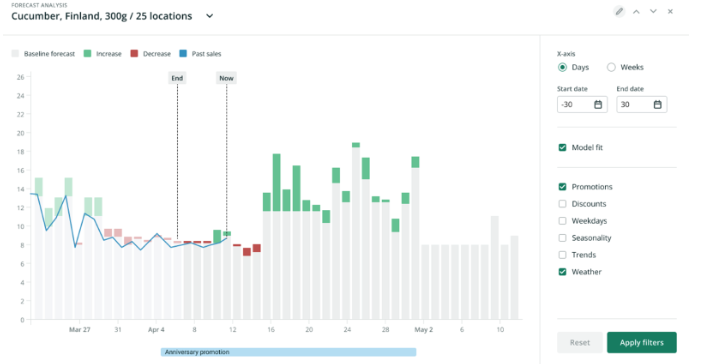
A transparent solution also gives planners valuable insights for further improvements — be it better data, the need for additional product classification, or testing new combinations of factors (such as adding a “lowest price” variable in our earlier example). Entirely less helpful is a “black box” system, where low transparency makes it impossible to understand why automated recommendations are being made. This lack of visibility quickly erodes user trust, often driving low system adoption rates.
3.3 Demand forecasting is only one part of retail planning and optimization
Keep in mind that while retail demand forecasting is essential, even great forecasts amount to nothing if they’re not used intelligently to guide business decisions. Users can and will add value in situations where they have information that the system does not since input data dictates the algorithm’s outputs.
When managing slow movers, for example, forecast accuracy is much less important to profitability than replenishment and space optimization, which will drive balanced, low-touch goods flows throughout the supply chain. Retail forerunners are applying AI across all their core planning processes — demand, operations, and merchandising – for improved profitability and sustainability.
The adoption of machine learning for demand forecasting lays the foundation for integrating advanced AI in retail. However, the potential applications of AI extend far beyond initial forecasting efforts. Advanced AI tools can address common planning challenges in predictive inventory management and supply chain and store diagnostics, including workforce optimization, in-store goods handling, and markdown strategy automation.
The evolution towards a more integrated application of AI in retail opens a vast array of opportunities for quick, impactful wins across the sector’s core functions, driving substantial improvements in efficiency and sustainability.
FAQ
1. What is machine learning?
Machine learning is an artificial intelligence function that allows a system to learn automatically and improve its recommendations using data alone, without any additional programming needed. It involves feeding large amounts of data into algorithms, which search for patterns and use these patterns to make better decisions. Machine learning is particularly valuable in industries that generate enormous amounts of data, such as retail, as it can quickly process and analyze this data to provide valuable insights and predictions.
2. How is machine learning used in demand forecasting?
Machine learning is used in demand forecasting to incorporate a wide range of factors and relationships that impact demand on a daily basis. Algorithms process large-scale data sets from various sources to refine machine learning models (sometimes ML models). These models help retailers predict daily product needs for each store location and channel. This ensures high availability for customers while maintaining minimal stock risk.
Machine learning models can also measure the impact of recurring patterns, internal business decisions, and external factors like weather, local events, and competitor activities. This helps to create more accurate, granular, and automated short- and long-term demand forecasts.
3. How can retailers address volatility in demand forecasting with machine learning?
Retail companies can use machine learning algorithms to analyze historical data to identify underlying patterns that traditional forecasting methods may overlook. These algorithms can also integrate variables such as market trends, consumer behavior, and external factors like weather or economic shifts. This approach enhances forecast accuracy and enables retailers to respond swiftly to changes in demand.
4. How can machine learning improve retail demand planning?
To use machine learning to improve retail demand planning, consider the following steps:
- Implement machine learning-powered demand forecasting technology to process and analyze large-scale data sets from various sources, including internal and external data streams.
- Leverage machine learning algorithms to capture the impact of recurring patterns, internal business decisions, and external factors on demand, ensuring more accurate and granular forecasts.
- Ensure the machine learning algorithms used are robust enough to avoid overfitting and can handle sparse data points, particularly for long-tail products.
- Combine machine learning with human expertise by using transparent solutions that allow planners to understand how forecasts are produced and enable them to fine-tune calculations based on their knowledge.
- Apply machine learning across all core planning processes, including demand, operations, and merchandising, for improved profitability and sustainability.
Incorporate machine learning into your retail demand planning process to achieve more accurate forecasts, optimize inventory levels, and improve overall supply chain efficiency.
Written by




